Transformer
Transformer의 특징을 알아보고 Pytorch로 구현된 코드를 리뷰해봅시다.
{kind=link}
Transformer
Transformer는 2017년 구글이 “Attention is All You Need” 논문에서 제안한 모델입니다. RNN을 사용하지 않고 오직 어텐션(Attention) 메커니즘만으로 인코더-디코더 구조를 구현하여 자연어 처리 분야에 혁명을 가져왔습니다. 이 글에서는 Transformer의 구조와 원리를 이해하고, PyTorch로 직접 구현해 보겠습니다.
1. Transformer의 등장 배경
기존의 sequence-to-sequence 모델은 RNN, LSTM, GRU 등의 순환 신경망을 기반으로 했습니다. 이런 모델들은 다음과 같은 한계가 있었습니다.
- 장기 의존성 문제(Long-term Dependency): 시퀀스가 길어질수록 초기 정보가 손실되는 문제
- 병렬 처리 불가: 순차적 연산으로 인한 학습 속도 저하
- 제한된 정보 전달: 인코더에서 디코더로 전달되는 context vector의 정보 병목 현상
Transformer는 이러한 문제들을 해결하기 위해 RNN을 완전히 제거하고, Self-Attention 메커니즘을 도입했습니다.
2. Transformer의 주요 요소와 핵심 아이디어
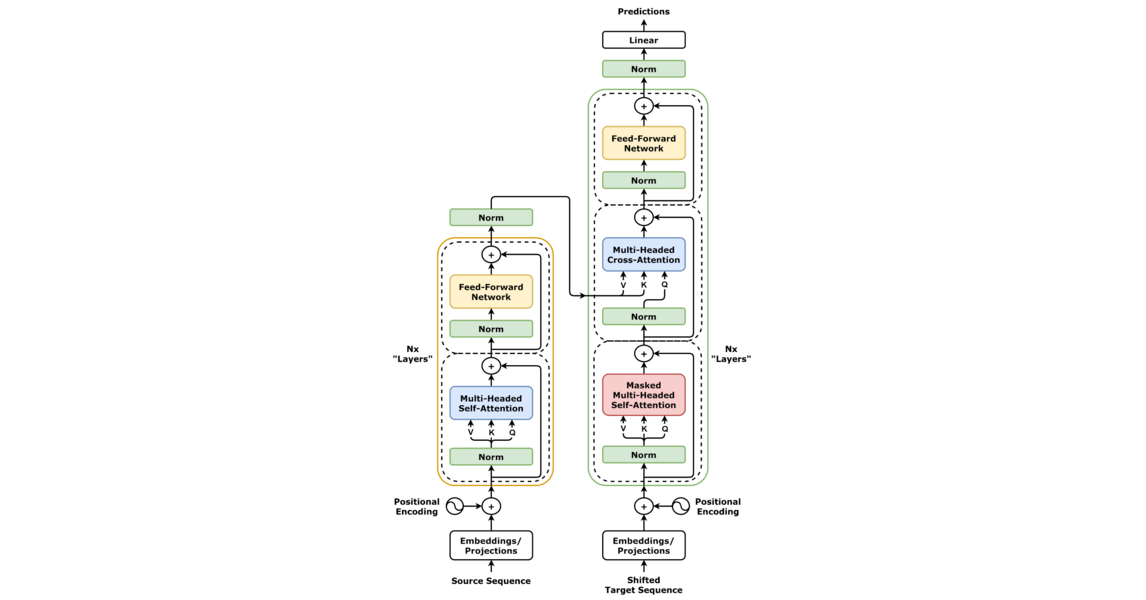
2.1 전체 아키텍처
Transformer는 인코더(Encoder)와 디코더(Decoder)로 구성됩니다.
![]()
Source: https://arxiv.org/abs/1706.03762
- 인코더: 입력 시퀀스를 처리하여 문맥 정보를 추출
- 디코더: 인코더의 출력을 바탕으로 출력 시퀀스를 생성
각각은 여러 개의 동일한 층(layer)으로 구성됩니다. 논문에서는 인코더와 디코더를 각각 6개 층으로 구성했습니다.
2.2 주요 하이퍼파라미터
![]()
Source: https://arxiv.org/abs/1706.03762
3. 핵심 요소별 설명 및 코드 리뷰
3.1 포지셔널 인코딩(Positional Encoding)
RNN과 달리 Transformer는 순차적으로 입력을 처리하지 않기 때문에, 단어의 위치 정보를 별도로 제공해야 합니다. 포지셔널 인코딩은 사인(sine)과 코사인(cosine) 함수를 사용하여 각 위치에 고유한 값을 부여합니다.
\[PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}})\] \[PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}})\] \[(pos: 위치\ 인덱스)\] \[(i: 차원\ 인덱스)\] \[(d_{model}: 모델의\ 차원)\]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
"""
포지셔널 인코딩 레이어: 입력 임베딩에 위치 정보를 추가합니다.
"""
def __init__(self, d_model, max_len=5000):
"""
Args:
d_model: 모델의 임베딩 차원 (int)
max_len: 최대 시퀀스 길이 (int)
"""
super(PositionalEncoding, self).__init__()
# 포지셔널 인코딩 행렬 생성
# pe 차원: [max_len, d_model]
pe = torch.zeros(max_len, d_model)
# position 차원: [max_len, 1]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# div_term 차원: [d_model/2]
# 주파수 간격을 로그 스케일로 계산 (2i 항목에 대한 계산)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 사인 함수를 짝수 인덱스에 적용
# pe[:, 0::2] 차원: [max_len, d_model/2]
# position * div_term 차원: [max_len, d_model/2]
pe[:, 0::2] = torch.sin(position * div_term)
# 코사인 함수를 홀수 인덱스에 적용
# pe[:, 1::2] 차원: [max_len, d_model/2]
pe[:, 1::2] = torch.cos(position * div_term)
# 차원 확장: [max_len, d_model] -> [1, max_len, d_model] -> [max_len, 1, d_model]
# 이는 배치 차원을 추가하기 위함입니다
pe = pe.unsqueeze(0).transpose(0, 1)
# 모델 파라미터가 아닌 버퍼로 등록 (학습되지 않음)
# self.pe 최종 차원: [max_len, 1, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: 입력 임베딩 [seq_len, batch_size, d_model]
- seq_len: 입력 시퀀스 길이
- batch_size: 배치 크기
- d_model: 모델의 임베딩 차원
Returns:
위치 정보가 추가된 임베딩 [seq_len, batch_size, d_model]
"""
# 입력에 포지셔널 인코딩 더하기
# self.pe[:x.size(0), :] 차원: [seq_len, 1, d_model]
# 브로드캐스팅으로 인해 batch_size 차원에 자동으로 확장됨
x = x + self.pe[:x.size(0), :] # 출력 차원: [seq_len, batch_size, d_model]
return x
3.2 스케일드 닷-프로덕트 어텐션(Scaled Dot-Product Attention)
Transformer의 핵심 연산은 스케일드 닷-프로덕트 어텐션입니다. 이 어텐션은 Query, Key, Value 세 가지 입력을 받습니다.
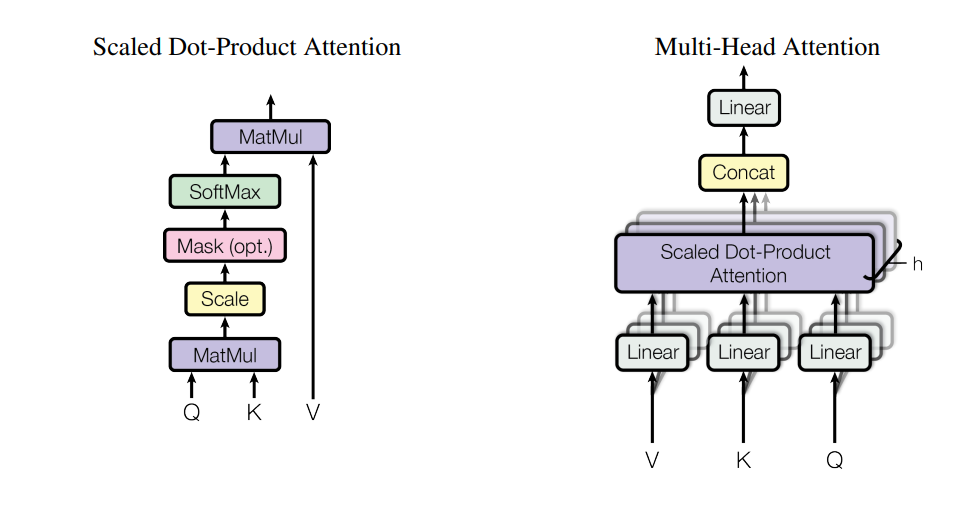
Source: https://arxiv.org/abs/1706.03762
스케일링 인자 \(\sqrt{d_k}\) 는 내적 값이 너무 커지는 것을 방지합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
def scaled_dot_product_attention(query, key, value, mask=None):
"""
스케일드 닷-프로덕트 어텐션을 계산합니다.
Transformer 모델의 핵심 어텐션 메커니즘입니다.
Args:
query: 쿼리 텐서 [batch_size, num_heads, seq_len_q, depth]
- batch_size: 배치 크기
- num_heads: 어텐션 헤드 수
- seq_len_q: 쿼리 시퀀스 길이
- depth: 각 헤드의 차원 (일반적으로 d_model/num_heads)
key: 키 텐서 [batch_size, num_heads, seq_len_k, depth]
- seq_len_k: 키 시퀀스 길이 (인코더-디코더 어텐션에서는 seq_len_q와 다를 수 있음)
value: 값 텐서 [batch_size, num_heads, seq_len_v, depth]
- seq_len_v: 값 시퀀스 길이 (일반적으로 seq_len_k와 동일)
mask: 마스킹을 위한 텐서 (옵션) [batch_size, 1, 1, seq_len_k] 또는 [batch_size, 1, seq_len_q, seq_len_k]
- 패딩 토큰 마스킹 또는 미래 토큰 마스킹(디코더에서)에 사용
Returns:
output: 어텐션 출력 [batch_size, num_heads, seq_len_q, depth]
attention_weights: 어텐션 가중치 [batch_size, num_heads, seq_len_q, seq_len_k]
"""
# Q와 K의 행렬 곱으로 어텐션 스코어 계산
# matmul_qk 차원: [batch_size, num_heads, seq_len_q, seq_len_k]
# key.transpose(-2, -1) 연산: [batch_size, num_heads, seq_len_k, depth] -> [batch_size, num_heads, depth, seq_len_k]
# 이는 내적 연산을 위해 key의 마지막 두 차원을 전치함
matmul_qk = torch.matmul(query, key.transpose(-2, -1))
# 스케일링 적용: 어텐션 스코어를 sqrt(d_k)로 나눔
# 이는 소프트맥스 함수의 기울기가 너무 작아지는 것을 방지 (Vaswani et al., 2017)
depth = key.size(-1) # depth = d_k (각 헤드의 차원)
scaled_attention_logits = matmul_qk / math.sqrt(depth)
# 마스킹 적용 (옵션)
# 마스크가 0인 위치에 매우 작은 값(-1e9)을 할당하여 소프트맥스 후 해당 위치의 가중치가 0에 가까워지도록 함
if mask is not None:
# mask 차원: [batch_size, 1, 1, seq_len_k] 또는 [batch_size, 1, seq_len_q, seq_len_k]
# masked_fill 연산: mask가 0인 위치에 -1e9(매우 작은 값)를 채움
scaled_attention_logits = scaled_attention_logits.masked_fill(mask == 0, -1e9)
# 소프트맥스로 어텐션 가중치 계산
# dim=-1은 마지막 차원(seq_len_k)에 대해 소프트맥스를 적용한다는 의미
# 이는 각 위치(쿼리)에 대해 모든 키의 가중치 합이 1이 되도록 정규화
# attention_weights 차원: [batch_size, num_heads, seq_len_q, seq_len_k]
attention_weights = F.softmax(scaled_attention_logits, dim=-1)
# 가중치와 Value의 곱
# output 차원: [batch_size, num_heads, seq_len_q, depth]
# 각 쿼리 위치에 대해 모든 value 벡터의 가중 평균을 계산
output = torch.matmul(attention_weights, value)
return output, attention_weights
3.3 멀티 헤드 어텐션(Multi-Head Attention)
멀티 헤드 어텐션은 어텐션 메커니즘을 여러 번 병렬로 수행하는 방식입니다. 이를 통해 다양한 표현 공간에서 정보를 추출할 수 있습니다.
\[MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O\] \[head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)\] \[(Wi^Q, Wi^K, Wi^V, W^O: 학습\ 가능한\ 가중치\ 행렬)\]이를 통해 다양한 표현 공간에서 정보를 추출할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
class MultiHeadAttention(nn.Module):
"""
멀티 헤드 어텐션 레이어: 여러 어텐션 헤드를 병렬로 계산합니다.
이는 서로 다른 표현 공간에서 정보를 추출하여 모델의 표현력을 높입니다.
"""
def __init__(self, d_model, num_heads, dropout=0.1):
"""
Args:
d_model: 모델의 임베딩 차원 (int)
num_heads: 어텐션 헤드 수 (int)
dropout: 드롭아웃 비율 (float)
"""
super(MultiHeadAttention, self).__init__()
# d_model이 num_heads로 나누어 떨어져야 각 헤드에 동일한 차원을 할당할 수 있음
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model # 모델 차원 (전체)
self.num_heads = num_heads # 어텐션 헤드 수
self.depth = d_model // num_heads # 각 헤드의 차원 (d_k)
# Query, Key, Value에 대한 선형 변환층
# 각 투영 행렬은 [d_model, d_model] 크기를 가지며,
# 내부적으로는 모든 헤드의 가중치를 합쳐서 표현
self.wq = nn.Linear(d_model, d_model) # Query 투영 행렬
self.wk = nn.Linear(d_model, d_model) # Key 투영 행렬
self.wv = nn.Linear(d_model, d_model) # Value 투영 행렬
# 출력을 위한 선형 변환층
# 모든 헤드의 출력을 결합한 후 원래 차원으로 투영
self.wo = nn.Linear(d_model, d_model) # 출력 투영 행렬
# 정규화를 위한 드롭아웃 레이어
self.dropout = nn.Dropout(dropout)
def split_heads(self, x, batch_size):
"""
텐서를 여러 헤드로 분할합니다.
d_model 차원을 num_heads와 depth로 재구성합니다.
Args:
x: 입력 텐서 [batch_size, seq_len, d_model]
- batch_size: 배치 크기
- seq_len: 시퀀스 길이
- d_model: 모델 차원
batch_size: 배치 크기
Returns:
분할된 텐서 [batch_size, num_heads, seq_len, depth]
"""
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, num_heads, depth]
# d_model 차원을 num_heads와 depth(d_k)로 분할
x = x.view(batch_size, -1, self.num_heads, self.depth)
# [batch_size, seq_len, num_heads, depth] -> [batch_size, num_heads, seq_len, depth]
# 차원 순서 변경: 헤드 차원을 두 번째 위치로 이동하여 각 헤드가 독립적으로 어텐션을 계산할 수 있게 함
return x.permute(0, 2, 1, 3)
def forward(self, query, key, value, mask=None):
"""
멀티 헤드 어텐션 계산을 수행합니다.
Args:
query: 쿼리 텐서 [batch_size, seq_len_q, d_model]
- seq_len_q: 쿼리 시퀀스 길이
key: 키 텐서 [batch_size, seq_len_k, d_model]
- seq_len_k: 키 시퀀스 길이
value: 값 텐서 [batch_size, seq_len_v, d_model]
- seq_len_v: 값 시퀀스 길이 (일반적으로 seq_len_k와 동일)
mask: 마스킹을 위한 텐서 (옵션)
- 패딩 마스크: [batch_size, 1, 1, seq_len_k]
- 미래 마스크: [batch_size, 1, seq_len_q, seq_len_k]
Returns:
output: 어텐션 결과 [batch_size, seq_len_q, d_model]
"""
batch_size = query.size(0)
# 선형 변환: 각 입력을 d_model 차원에서 d_model 차원으로 투영
# 내부적으로는 각 헤드별로 서로 다른 투영 공간을 사용함
q = self.wq(query) # [batch_size, seq_len_q, d_model]
k = self.wk(key) # [batch_size, seq_len_k, d_model]
v = self.wv(value) # [batch_size, seq_len_v, d_model]
# 헤드 분할: 투영된 텐서를 여러 헤드로 분할
q = self.split_heads(q, batch_size) # [batch_size, num_heads, seq_len_q, depth]
k = self.split_heads(k, batch_size) # [batch_size, num_heads, seq_len_k, depth]
v = self.split_heads(v, batch_size) # [batch_size, num_heads, seq_len_v, depth]
# 스케일드 닷-프로덕트 어텐션 계산
# 각 헤드는 독립적으로 어텐션을 계산
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
# scaled_attention: [batch_size, num_heads, seq_len_q, depth]
# attention_weights: [batch_size, num_heads, seq_len_q, seq_len_k]
# 헤드 결합: 여러 헤드의 결과를 하나로 결합
# [batch_size, num_heads, seq_len_q, depth] -> [batch_size, seq_len_q, num_heads, depth]
# 헤드 차원을 다시 세 번째 위치로 이동
scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous()
# [batch_size, seq_len_q, num_heads, depth] -> [batch_size, seq_len_q, d_model]
# num_heads와 depth 차원을 합쳐서 원래 d_model 차원으로 복원
concat_attention = scaled_attention.view(batch_size, -1, self.d_model)
# 최종 선형 변환: 결합된 헤드를 출력 공간으로 투영
output = self.wo(concat_attention) # [batch_size, seq_len_q, d_model]
# 여기서 self.dropout을 적용하지 않음 (일반적으로는 적용할 수 있음)
return output
3.4 피드 포워드 네트워크(Feed-Forward Network)
각 인코더/디코더 층에는 2개의 선형 변환과 ReLU 활성화 함수로 구성된 피드 포워드 네트워크가 포함됩니다.
\[FFN(x) = max(0, xW_1 + b_1)W_2 + b_2\]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
class PositionwiseFeedForward(nn.Module):
"""
포지션 와이즈 피드 포워드 네트워크: 두 개의 선형 변환과 ReLU 활성화 함수로 구성됩니다.
Transformer에서 각 위치(토큰)에 독립적으로 적용되는 정보 처리 레이어입니다.
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂ 수식을 구현합니다.
"""
def __init__(self, d_model, d_ff, dropout=0.1):
"""
Args:
d_model: 모델의 임베딩 차원 (int)
- 입력과 출력의 차원
d_ff: 피드 포워드 네트워크의 내부 차원 (int)
- 일반적으로 d_model보다 크게 설정 (보통 4배)
dropout: 드롭아웃 비율 (float)
- 과적합 방지를 위한 정규화 파라미터
"""
super(PositionwiseFeedForward, self).__init__()
# 첫 번째 선형 변환: d_model -> d_ff로 확장
# 차원을 확장하여 더 풍부한 표현력을 갖도록 함
self.linear1 = nn.Linear(d_model, d_ff) # 가중치 차원: [d_model, d_ff]
# 두 번째 선형 변환: d_ff -> d_model로 축소
# 확장된 표현을 다시 원래 모델 차원으로 압축
self.linear2 = nn.Linear(d_ff, d_model) # 가중치 차원: [d_ff, d_model]
# 드롭아웃 레이어: 과적합 방지
# 첫 번째 선형 변환 후에 적용됨
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
포지션 와이즈 피드 포워드 네트워크의 순전파 연산을 수행합니다.
각 위치(토큰)는 독립적으로 처리됩니다.
Args:
x: 입력 텐서 [batch_size, seq_len, d_model]
- batch_size: 배치 크기
- seq_len: 시퀀스 길이
- d_model: 모델 차원
Returns:
변환된 텐서 [batch_size, seq_len, d_model]
- 입력과 동일한 shape을 유지하며 내용만 변환
"""
# 첫 번째 선형 변환 후 ReLU 활성화
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, d_ff]
# ReLU는 max(0, x) 연산으로, 음수 값을 0으로 만들고 양수 값은 그대로 유지
x = F.relu(self.linear1(x))
# 드롭아웃 적용: 훈련 중에만 일부 뉴런을 비활성화
# 테스트 시에는 모든 뉴런이 활성화됨
# [batch_size, seq_len, d_ff] 차원 유지
x = self.dropout(x)
# 두 번째 선형 변환: 원래 차원으로 복원
# [batch_size, seq_len, d_ff] -> [batch_size, seq_len, d_model]
x = self.linear2(x)
return x
3.5 정규화 레이어(Layer Normalization)
각 서브레이어 후에는 층 정규화(Layer Normalization)가 적용됩니다. 이는 학습을 안정화하고 기울기 소실 문제를 완화합니다.
\[\text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta\] \[(μ: 평균)\] \[(σ: 표준편차)\] \[(γ, β: 학습\ 가능한\ 파라미터)\] \[(ϵ: 수치\ 안정성을\ 위한\ 작은\ 상수)\]학습을 안정화하고 기울기 소실 문제를 완화하는 역할을 합니다.
1
2
3
# 레이어 정규화 적용 예시
layer_norm = nn.LayerNorm(d_model, eps=1e-6)
normalized_x = layer_norm(x + sublayer_output) # 잔차 연결 및 정규화
3.6 인코더 레이어(Encoder Layer)
각 인코더 레이어는 멀티 헤드 셀프 어텐션과 피드 포워드 네트워크로 구성됩니다. 두 서브레이어 모두 잔차 연결(residual connection)과 층 정규화(layer normalization)가 적용됩니다.
\[\text{EncoderLayer(x)}=LayerNorm(x+MultiHeadAttention(x,x,x))\] \[\text{Output} = \text{LayerNorm}(\text{EncoderLayer}(x) + \text{FeedForward}(\text{EncoderLayer}(x)))\]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
class EncoderLayer(nn.Module):
"""
인코더 레이어: 멀티 헤드 셀프 어텐션과 피드 포워드 네트워크로 구성됩니다.
Transformer 인코더의 핵심 구성 요소로, 각 인코더 레이어는 동일한 구조를 가집니다.
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
"""
Args:
d_model: 모델의 임베딩 차원 (int)
num_heads: 어텐션 헤드 수 (int)
d_ff: 피드 포워드 네트워크의 내부 차원 (int)
dropout: 드롭아웃 비율 (float)
"""
super(EncoderLayer, self).__init__()
# 멀티 헤드 어텐션 레이어 (셀프 어텐션에 사용)
# 동일한 시퀀스 내의 토큰 간 관계를 모델링
self.mha = MultiHeadAttention(d_model, num_heads, dropout)
# 피드 포워드 네트워크
# 각 위치(토큰)별로 독립적으로 적용되는 비선형 변환
self.ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
# 레이어 정규화 - 첫 번째 서브레이어 후
# 출력 분포를 정규화하여 학습 안정성 향상
self.norm1 = nn.LayerNorm(d_model, eps=1e-6)
# 레이어 정규화 - 두 번째 서브레이어 후
self.norm2 = nn.LayerNorm(d_model, eps=1e-6)
# 드롭아웃 - 첫 번째 서브레이어 출력에 적용
# 과적합 방지를 위한 정규화 기법
self.dropout1 = nn.Dropout(dropout)
# 드롭아웃 - 두 번째 서브레이어 출력에 적용
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
인코더 레이어의 순전파 연산을 수행합니다.
Args:
x: 입력 텐서 [batch_size, seq_len, d_model]
- batch_size: 배치 크기
- seq_len: 입력 시퀀스 길이
- d_model: 모델 차원
mask: 마스킹을 위한 텐서 (옵션)
- 패딩 마스크: [batch_size, 1, 1, seq_len]
- 시퀀스 내 특정 토큰 간 어텐션을 방지
Returns:
출력 텐서 [batch_size, seq_len, d_model]
- 입력과 동일한 차원을 유지
"""
# 멀티 헤드 셀프 어텐션 (첫 번째 서브레이어)
# x를 query, key, value로 모두 사용 (셀프 어텐션)
# 입력: x [batch_size, seq_len, d_model]
# 출력: attn_output [batch_size, seq_len, d_model]
attn_output = self.mha(x, x, x, mask)
# 드롭아웃, 잔차 연결, 레이어 정규화
# 1. self.dropout1(attn_output): 어텐션 출력에 드롭아웃 적용 [batch_size, seq_len, d_model]
# 2. x + dropout_output: 잔차 연결 (입력과 출력을 더함) [batch_size, seq_len, d_model]
# 3. self.norm1(...): 레이어 정규화 적용 [batch_size, seq_len, d_model]
out1 = self.norm1(x + self.dropout1(attn_output))
# 피드 포워드 네트워크 (두 번째 서브레이어)
# 입력: out1 [batch_size, seq_len, d_model]
# 내부에서 차원 확장: [batch_size, seq_len, d_ff]
# 출력: ffn_output [batch_size, seq_len, d_model]
ffn_output = self.ffn(out1)
# 드롭아웃, 잔차 연결, 레이어 정규화
# 1. self.dropout2(ffn_output): FFN 출력에 드롭아웃 적용 [batch_size, seq_len, d_model]
# 2. out1 + dropout_output: 잔차 연결 (첫 서브레이어 출력과 FFN 출력을 더함) [batch_size, seq_len, d_model]
# 3. self.norm2(...): 레이어 정규화 적용 [batch_size, seq_len, d_model]
out2 = self.norm2(out1 + self.dropout2(ffn_output))
return out2 # [batch_size, seq_len, d_model]
3.7 디코더 레이어(Decoder Layer)
각 디코더 레이어는 세 개의 서브레이어로 구성됩니다.
- 마스크드 멀티 헤드 셀프 어텐션
- 인코더-디코더 멀티 헤드 어텐션
- 피드 포워드 네트워크
모든 서브레이어에 잔차 연결과 층 정규화가 적용됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
class DecoderLayer(nn.Module):
"""
디코더 레이어: 마스크드 멀티 헤드 셀프 어텐션, 인코더-디코더 어텐션, 피드 포워드 네트워크로 구성됩니다.
Transformer 디코더의 핵심 구성 요소로, 시퀀스 생성 및 인코더 정보 활용에 사용됩니다.
"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
"""
Args:
d_model: 모델의 임베딩 차원 (int)
num_heads: 어텐션 헤드 수 (int)
d_ff: 피드 포워드 네트워크의 내부 차원 (int)
dropout: 드롭아웃 비율 (float)
"""
super(DecoderLayer, self).__init__()
# 마스크드 멀티 헤드 셀프 어텐션
# 디코더 자신의 이전 출력 토큰들 간의 관계를 모델링
# 미래 토큰에 대한 정보 유출을 방지하는 look-ahead 마스크 사용
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
# 인코더-디코더 멀티 헤드 어텐션
# 디코더가 인코더의 출력 정보를 활용하기 위한 어텐션
# 디코더의 쿼리가 인코더의 키와 값에 어텐션을 수행
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
# 피드 포워드 네트워크
# 각 위치(토큰)별로 독립적으로 적용되는 비선형 변환
self.ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
# 레이어 정규화 - 첫 번째 서브레이어 후 (셀프 어텐션)
self.norm1 = nn.LayerNorm(d_model, eps=1e-6)
# 레이어 정규화 - 두 번째 서브레이어 후 (인코더-디코더 어텐션)
self.norm2 = nn.LayerNorm(d_model, eps=1e-6)
# 레이어 정규화 - 세 번째 서브레이어 후 (피드 포워드)
self.norm3 = nn.LayerNorm(d_model, eps=1e-6)
# 드롭아웃 - 각 서브레이어 출력에 적용
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, look_ahead_mask=None, padding_mask=None):
"""
디코더 레이어의 순전파 연산을 수행합니다.
Args:
x: 디코더 입력 [batch_size, seq_len, d_model]
- batch_size: 배치 크기
- seq_len: 디코더 입력 시퀀스 길이 (타겟 시퀀스)
- d_model: 모델 차원
enc_output: 인코더 출력 [batch_size, enc_seq_len, d_model]
- enc_seq_len: 인코더 시퀀스 길이 (소스 시퀀스)
- 일반적으로 enc_seq_len과 seq_len은 다를 수 있음
look_ahead_mask: 룩-어헤드 마스크 [batch_size, 1, seq_len, seq_len]
- 미래 토큰을 가리기 위한 마스크 (자기회귀 속성 유지)
- 디코더는 현재 위치까지의 출력만 볼 수 있음
padding_mask: 패딩 마스크 [batch_size, 1, 1, enc_seq_len]
- 인코더 출력의 패딩 토큰을 가리기 위한 마스크
Returns:
출력 텐서 [batch_size, seq_len, d_model]
"""
# 마스크드 멀티 헤드 셀프 어텐션 (첫 번째 서브레이어)
# 입력: x [batch_size, seq_len, d_model]
# 마스크: look_ahead_mask [batch_size, 1, seq_len, seq_len]
# 출력: self_attn_output [batch_size, seq_len, d_model]
self_attn_output = self.self_attn(x, x, x, look_ahead_mask)
# 드롭아웃, 잔차 연결, 레이어 정규화
# 1. self.dropout1(self_attn_output): 드롭아웃 적용 [batch_size, seq_len, d_model]
# 2. x + dropout_output: 잔차 연결 [batch_size, seq_len, d_model]
# 3. self.norm1(...): 레이어 정규화 [batch_size, seq_len, d_model]
out1 = self.norm1(x + self.dropout1(self_attn_output))
# 인코더-디코더 멀티 헤드 어텐션 (두 번째 서브레이어)
# Query: out1 [batch_size, seq_len, d_model] (디코더의 이전 출력)
# Key, Value: enc_output [batch_size, enc_seq_len, d_model] (인코더의 출력)
# 마스크: padding_mask [batch_size, 1, 1, enc_seq_len]
# 출력: cross_attn_output [batch_size, seq_len, d_model]
cross_attn_output = self.cross_attn(out1, enc_output, enc_output, padding_mask)
# 드롭아웃, 잔차 연결, 레이어 정규화
# 1. self.dropout2(cross_attn_output): 드롭아웃 적용 [batch_size, seq_len, d_model]
# 2. out1 + dropout_output: 잔차 연결 [batch_size, seq_len, d_model]
# 3. self.norm2(...): 레이어 정규화 [batch_size, seq_len, d_model]
out2 = self.norm2(out1 + self.dropout2(cross_attn_output))
# 피드 포워드 네트워크 (세 번째 서브레이어)
# 입력: out2 [batch_size, seq_len, d_model]
# 내부 확장: [batch_size, seq_len, d_ff] (FFN 내부에서 확장)
# 출력: ffn_output [batch_size, seq_len, d_model]
ffn_output = self.ffn(out2)
# 드롭아웃, 잔차 연결, 레이어 정규화
# 1. self.dropout3(ffn_output): 드롭아웃 적용 [batch_size, seq_len, d_model]
# 2. out2 + dropout_output: 잔차 연결 [batch_size, seq_len, d_model]
# 3. self.norm3(...): 레이어 정규화 [batch_size, seq_len, d_model]
out3 = self.norm3(out2 + self.dropout3(ffn_output))
return out3 # [batch_size, seq_len, d_model]
3.8 전체 인코더(Encoder)
전체 인코더는 N개의 동일한 인코더 레이어를 쌓아서 구성됩니다. 각 레이어는 이전 레이어의 출력을 입력으로 받습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
class Encoder(nn.Module):
"""
Transformer 인코더: N개의 인코더 레이어를 쌓아 구성합니다.
입력 시퀀스를 처리하여 문맥 정보를 추출합니다.
"""
def __init__(self, n_layers, d_model, num_heads, d_ff, input_vocab_size, max_seq_len, dropout=0.1):
"""
Args:
n_layers: 인코더 레이어 수 (int)
d_model: 모델의 임베딩 차원 (int)
num_heads: 어텐션 헤드 수 (int)
d_ff: 피드 포워드 네트워크의 내부 차원 (int)
input_vocab_size: 입력 어휘 크기 (int)
max_seq_len: 최대 시퀀스 길이 (int)
dropout: 드롭아웃 비율 (float)
"""
super(Encoder, self).__init__()
# 단어 임베딩 레이어: 정수 인덱스를 d_model 차원의 벡터로 변환
self.embedding = nn.Embedding(input_vocab_size, d_model)
# 포지셔널 인코딩: 위치 정보 추가
self.pos_encoding = PositionalEncoding(d_model, max_seq_len)
# 인코더 레이어 스택: n_layers개의 인코더 레이어
self.encoder_layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(n_layers)
])
# 드롭아웃 레이어: 임베딩 및 포지셔널 인코딩 후 적용
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
인코더의 순전파 연산을 수행합니다.
Args:
x: 입력 텐서 [batch_size, seq_len]
- 정수 인덱스로 표현된 입력 토큰
mask: 마스킹을 위한 텐서 (패딩 마스크) (옵션)
- [batch_size, 1, 1, seq_len]
Returns:
인코더 출력 [batch_size, seq_len, d_model]
"""
# 임베딩 및 스케일링
# [batch_size, seq_len] -> [batch_size, seq_len, d_model]
# sqrt(d_model)로 스케일링하여 임베딩의 크기가 너무 커지는 것을 방지
seq_len = x.size(1)
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
# 포지셔널 인코딩 추가
# [batch_size, seq_len, d_model]에 위치 정보 추가
x = self.pos_encoding(x)
# 드롭아웃 적용
x = self.dropout(x)
# N개의 인코더 레이어를 차례로 통과
# 각 레이어는 입력과 동일한 차원의 출력을 생성 [batch_size, seq_len, d_model]
for layer in self.encoder_layers:
x = layer(x, mask)
# 최종 인코더 출력 [batch_size, seq_len, d_model]
return x
3.9 전체 디코더(Decoder)
전체 디코더는 N개의 동일한 디코더 레이어를 쌓아서 구성됩니다. 각 레이어는 이전 레이어의 출력과 인코더의 출력을 입력으로 받습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
class Decoder(nn.Module):
"""
Transformer 디코더: N개의 디코더 레이어를 쌓아 구성합니다.
인코더의 출력을 바탕으로 출력 시퀀스를 생성합니다.
"""
def __init__(self, n_layers, d_model, num_heads, d_ff, target_vocab_size, max_seq_len, dropout=0.1):
"""
Args:
n_layers: 디코더 레이어 수 (int)
d_model: 모델의 임베딩 차원 (int)
num_heads: 어텐션 헤드 수 (int)
d_ff: 피드 포워드 네트워크의 내부 차원 (int)
target_vocab_size: 출력 어휘 크기 (int)
max_seq_len: 최대 시퀀스 길이 (int)
dropout: 드롭아웃 비율 (float)
"""
super(Decoder, self).__init__()
# 단어 임베딩 레이어: 정수 인덱스를 d_model 차원의 벡터로 변환
self.embedding = nn.Embedding(target_vocab_size, d_model)
# 포지셔널 인코딩: 위치 정보 추가
self.pos_encoding = PositionalEncoding(d_model, max_seq_len)
# 디코더 레이어 스택: n_layers개의 디코더 레이어
self.decoder_layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(n_layers)
])
# 드롭아웃 레이어: 임베딩 및 포지셔널 인코딩 후 적용
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, look_ahead_mask=None, padding_mask=None):
"""
디코더의 순전파 연산을 수행합니다.
Args:
x: 디코더 입력 텐서 [batch_size, seq_len]
- 정수 인덱스로 표현된 타겟 토큰
enc_output: 인코더 출력 [batch_size, inp_seq_len, d_model]
look_ahead_mask: 룩어헤드 마스크 [batch_size, 1, seq_len, seq_len]
- 자기회귀 속성을 위한 미래 토큰 마스킹
padding_mask: 패딩 마스크 [batch_size, 1, 1, inp_seq_len]
- 인코더 출력의 패딩 토큰 마스킹
Returns:
디코더 출력 [batch_size, seq_len, d_model]
"""
# 임베딩 및 스케일링
# [batch_size, seq_len] -> [batch_size, seq_len, d_model]
seq_len = x.size(1)
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
# 포지셔널 인코딩 추가
# [batch_size, seq_len, d_model]에 위치 정보 추가
x = self.pos_encoding(x)
# 드롭아웃 적용
x = self.dropout(x)
# N개의 디코더 레이어를 차례로 통과
# 각 레이어는 입력, 인코더 출력, 그리고 두 가지 마스크를 사용
for layer in self.decoder_layers:
x = layer(x, enc_output, look_ahead_mask, padding_mask)
# 최종 디코더 출력 [batch_size, seq_len, d_model]
return x
3.10 완전한 Transformer(Transformer)
마지막으로, 전체 Transformer 모델은 인코더, 디코더, 그리고 최종 선형 레이어로 구성됩니다. 최종 선형 레이어는 디코더의 출력을 타겟 어휘 크기의 로짓(logit) 값으로 변환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
class Transformer(nn.Module):
"""
완전한 Transformer 모델: 인코더, 디코더, 최종 선형 레이어로 구성됩니다.
시퀀스-투-시퀀스 태스크(번역, 요약 등)를 위한 모델입니다.
"""
def __init__(self, n_layers, d_model, num_heads, d_ff, input_vocab_size,
target_vocab_size, max_seq_len, dropout=0.1):
"""
Args:
n_layers: 인코더/디코더 레이어 수 (int)
d_model: 모델의 임베딩 차원 (int)
num_heads: 어텐션 헤드 수 (int)
d_ff: 피드 포워드 네트워크의 내부 차원 (int)
input_vocab_size: 입력 어휘 크기 (int)
target_vocab_size: 출력 어휘 크기 (int)
max_seq_len: 최대 시퀀스 길이 (int)
dropout: 드롭아웃 비율 (float)
"""
super(Transformer, self).__init__()
# 인코더: 입력 시퀀스를 처리
self.encoder = Encoder(n_layers, d_model, num_heads, d_ff,
input_vocab_size, max_seq_len, dropout)
# 디코더: 타겟 시퀀스와 인코더 출력을 처리
self.decoder = Decoder(n_layers, d_model, num_heads, d_ff,
target_vocab_size, max_seq_len, dropout)
# 최종 선형 레이어: 디코더 출력을 타겟 어휘 로짓으로 변환
self.final_layer = nn.Linear(d_model, target_vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, mem_mask=None):
"""
Transformer의 순전파 연산을 수행합니다.
Args:
src: 인코더 입력 텐서 [batch_size, src_seq_len]
- 소스 시퀀스(예: 영어 문장)
tgt: 디코더 입력 텐서 [batch_size, tgt_seq_len]
- 타겟 시퀀스(예: 한국어 문장)
src_mask: 소스 패딩 마스크 [batch_size, 1, 1, src_seq_len]
tgt_mask: 타겟 룩어헤드 마스크 [batch_size, 1, tgt_seq_len, tgt_seq_len]
mem_mask: 메모리(인코더 출력) 패딩 마스크 [batch_size, 1, 1, src_seq_len]
Returns:
최종 출력 로짓 [batch_size, tgt_seq_len, target_vocab_size]
"""
# 1. 인코더 통과
# 소스 시퀀스를 처리하여 문맥 표현 생성
# [batch_size, src_seq_len] -> [batch_size, src_seq_len, d_model]
enc_output = self.encoder(src, src_mask)
# 2. 디코더 통과
# 타겟 시퀀스와 인코더 출력을 처리
# [batch_size, tgt_seq_len] -> [batch_size, tgt_seq_len, d_model]
dec_output = self.decoder(tgt, enc_output, tgt_mask, mem_mask)
# 3. 최종 선형 레이어
# 디코더 출력을 타겟 어휘 로짓으로 변환
# [batch_size, tgt_seq_len, d_model] -> [batch_size, tgt_seq_len, target_vocab_size]
output = self.final_layer(dec_output)
return output
def generate(self, src, src_mask=None, max_len=100, start_token=1, end_token=2):
"""
자동 회귀(Autoregressive) 방식으로 시퀀스를 생성합니다.
Args:
src: 인코더 입력 텐서 [batch_size, src_seq_len]
src_mask: 소스 패딩 마스크 [batch_size, 1, 1, src_seq_len]
max_len: 생성할 최대 시퀀스 길이 (int)
start_token: 시작 토큰 ID (int)
end_token: 종료 토큰 ID (int)
Returns:
생성된 시퀀스 [batch_size, out_seq_len]
"""
batch_size = src.size(0)
device = src.device
# 인코더 출력 계산 (한 번만 수행)
enc_output = self.encoder(src, src_mask)
# 디코더 시작 토큰으로 초기화
ys = torch.ones(batch_size, 1).fill_(start_token).long().to(device)
# 자동 회귀적 생성
for i in range(max_len-1):
# 타겟 마스크 생성 (룩어헤드 마스크)
tgt_mask = self.generate_square_subsequent_mask(ys.size(1)).to(device)
# 디코더 출력 계산
out = self.decoder(ys, enc_output, tgt_mask, src_mask)
# 최종 선형 레이어 통과
out = self.final_layer(out)
# 마지막 토큰에 대한 예측 확률 계산
prob = F.softmax(out[:, -1], dim=-1)
# 가장 확률이 높은 토큰 선택
_, next_token = torch.max(prob, dim=1)
next_token = next_token.unsqueeze(1)
# 시퀀스에 새 토큰 추가
ys = torch.cat([ys, next_token], dim=1)
# 종료 토큰이 생성되면 중단
if (next_token == end_token).sum() == batch_size:
break
return ys
@staticmethod
def generate_square_subsequent_mask(sz):
"""
룩어헤드 마스크를 생성합니다 (디코더의 자기회귀 속성을 위함).
Args:
sz: 시퀀스 길이 (int)
Returns:
마스크 텐서 [1, sz, sz]
"""
# 하삼각 행렬 생성 (대각선 포함)
mask = torch.triu(torch.ones(sz, sz), diagonal=1)
# True를 0으로, False를 1로 변환
mask = (mask == 0).float().unsqueeze(0)
return mask
4. Transformer 모델 초기화 및 사용 예시
다음은 Transformer 모델을 초기화하고 사용하는 간단한 예시입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 하이퍼파라미터 설정
n_layers = 6 # 인코더/디코더 레이어 수
d_model = 512 # 모델 차원
num_heads = 8 # 어텐션 헤드 수
d_ff = 2048 # 피드 포워드 네트워크 차원
input_vocab_size = 10000 # 입력 어휘 크기
target_vocab_size = 10000 # 출력 어휘 크기
max_seq_len = 100 # 최대 시퀀스 길이
dropout = 0.1 # 드롭아웃 비율
# Transformer 모델 초기화
transformer = Transformer(
n_layers=n_layers,
d_model=d_model,
num_heads=num_heads,
d_ff=d_ff,
input_vocab_size=input_vocab_size,
target_vocab_size=target_vocab_size,
max_seq_len=max_seq_len,
dropout=dropout
)
# 가상의 입력 데이터 (배치 크기 = 16, 시퀀스 길이 = 20)
src = torch.randint(1, input_vocab_size, (16, 20)) # [batch_size=16, src_seq_len=20]
tgt = torch.randint(1, target_vocab_size, (16, 20)) # [batch_size=16, tgt_seq_len=20]
# 마스크 생성
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # [batch_size=16, 1, 1, src_seq_len=20] - 패딩 마스크
tgt_mask = transformer.generate_square_subsequent_mask(tgt.size(1)) # [1, tgt_seq_len=20, tgt_seq_len=20] - 룩어헤드 마스크
mem_mask = src_mask # [batch_size=16, 1, 1, src_seq_len=20] - 메모리 마스크 (인코더 출력에 대한 패딩 마스크)
# 모델 순전파
output = transformer(src, tgt, src_mask, tgt_mask, mem_mask) # [batch_size=16, tgt_seq_len=20, target_vocab_size=10000]
# 출력 형태 확인
print(f"Input shape: {src.shape}") # [16, 20]
print(f"Output shape: {output.shape}") # [16, 20, 10000]
# 시퀀스 생성 예시
generated = transformer.generate(src, src_mask) # [batch_size=16, max_len(또는 종료 토큰이 나올 때까지의 길이)]
print(f"Generated sequence shape: {generated.shape}") # 예: [16, 생성된_시퀀스_길이]
5. Transformer의 학습 및 추론
5.1 손실 함수
Transformer 모델은 일반적으로 Cross-Entropy Loss를 사용하여 학습됩니다. 이는 모델이 각 위치에서 다음 토큰을 올바르게 예측하도록 훈련시킵니다.
1
2
3
4
5
6
7
8
# 손실 함수 정의
criterion = nn.CrossEntropyLoss(ignore_index=0) # 패딩 토큰(0)은 무시
# 손실 계산 예시
# output: [batch_size, tgt_seq_len, target_vocab_size]
# target: [batch_size, tgt_seq_len]
loss = criterion(output.view(-1, target_vocab_size), tgt.view(-1))
# view 후: output: [batch_size*tgt_seq_len, target_vocab_size], tgt: [batch_size*tgt_seq_len]
5.2 학습 과정
Transformer의 학습 과정입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 옵티마이저 설정
optimizer = torch.optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# 학습 루프
def train_epoch(model, dataloader, optimizer, criterion, device):
model.train()
total_loss = 0
for batch in dataloader:
# 배치 데이터 추출
src, tgt = batch # src: [batch_size, src_seq_len], tgt: [batch_size, tgt_seq_len]
src, tgt = src.to(device), tgt.to(device)
# 타겟 입력과 타겟 출력 분리
# 디코더 입력: 시작 토큰 ~ 마지막 토큰 이전
# 디코더 출력(정답): 시작 토큰 이후 ~ 마지막 토큰
tgt_inp = tgt[:, :-1] # [batch_size, tgt_seq_len-1]
tgt_out = tgt[:, 1:] # [batch_size, tgt_seq_len-1]
# 마스크 생성
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # [batch_size, 1, 1, src_seq_len]
tgt_mask = model.generate_square_subsequent_mask(tgt_inp.size(1)).to(device) # [1, tgt_seq_len-1, tgt_seq_len-1]
# 모델 순전파
output = model(src, tgt_inp, src_mask, tgt_mask, src_mask) # [batch_size, tgt_seq_len-1, target_vocab_size]
# 손실 계산
loss = criterion(output.reshape(-1, output.size(-1)), tgt_out.reshape(-1))
# reshape 후: output: [batch_size*(tgt_seq_len-1), target_vocab_size], tgt_out: [batch_size*(tgt_seq_len-1)]
# 역전파 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
5.3 추론 (번역 예시)
학습된 Transformer 모델을 사용한 추론 과정입니다. 아래 예시는 영어에서 한국어로의 번역 태스크를 가정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def translate(model, src_sentence, src_tokenizer, tgt_tokenizer, device, max_len=100):
model.eval()
# 소스 문장 토큰화
tokens = src_tokenizer.encode(src_sentence) # [토큰 수]
src = torch.tensor([tokens]).to(device) # [1, src_seq_len]
# 소스 마스크 생성
src_mask = (src != 0).unsqueeze(1).unsqueeze(2).to(device) # [1, 1, 1, src_seq_len]
# 시퀀스 생성
output = model.generate(src, src_mask, max_len=max_len) # [1, 생성된_시퀀스_길이]
# 결과 디코딩
translated = tgt_tokenizer.decode(output[0].tolist()) # 문자열
return translated
마치며
오늘은 LLM들의 기초가 되는 Transformer의 특징을 알아보고 이를 Pytorch로 구현한 코드에 대해 자세히 리뷰해보았습니다. 이를 통해 ‘Next Token Generation’의 Task를 수행하는 원리에 대해 다시 한번 확인할 수 있었습니다.
내부적으로 상당히 복잡하기 때문에 한번에 이해하기는 쉽지 않지만 여러번 디버깅해보며 꽤 깊이 있게 알게 되었네요. 감사합니다.