Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Sentence-BERT 논문을 읽고 핵심 내용을 짚어봅니다.
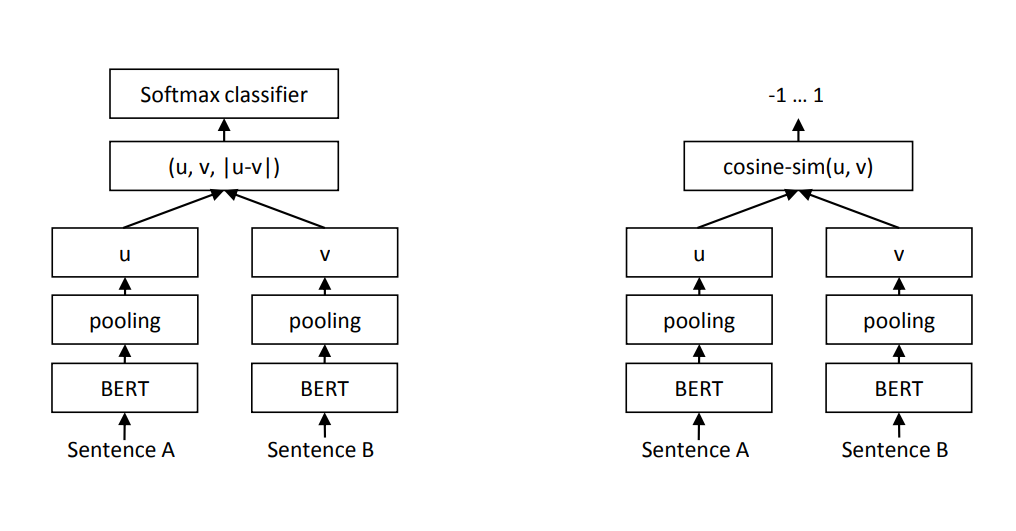
Source: https://arxiv.org/pdf/1908.10084
Sentence-BERT
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks을 자세히 살펴보고 중요한 내용를 정리합니다.
Abstract
“BERT (Devlin et al., 2018) and RoBERTa (Liu et al., 2019) has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT. The construction of BERT makes it unsuitable for semantic similarity search as well as for unsupervised tasks like clustering.”
저자들은 BERT, RoBERTa 아키텍처들이 문장과 문장간의 유사성을 구하는 STS task에서 sota 성능을 달성했지만, 이 모델들은 두 문장을 한번에 네트워크에 입력하기 때문에 계산하는데 큰 overhead를 발생시킨다고 언급하고 있습니다. 또한 문장간의 유사성을 구하거나 비지도 학습 기반 task를 수행하는데 적합하지 않다고 주장합니다.
“In this publication, we present Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT. We evaluate SBERT and SRoBERTa on common (전이학습 + STS 데이터셋 기준) STS tasks and transfer learning tasks, where it outperforms other state-of-th
저자들은 이를 개선하기 위한 ‘Sentence-BERT(SBERT)’를 제안합니다. ‘siamese’ 및 ‘triplet’ 구조를 사용하여 문장 임베딩을 표현한다고 합니다. 해당 방법을 통해 유사한 문장을 찾는 시간을 (전이학습 + STS 데이터셋 기준) BERT/RoBERTa의 65시간에서 SBERT의 5초로 최적화하면서 BERT의 정확도는 유지한다고 언급합니다.
1. Introduction
“BERT set new state-of-the-art performance on various sentence classification and sentence-pair regression tasks. BERT uses a cross-encoder: Two sentences are passed to the transformer network and the target value is predicted. However, this setup is unsuitable for various pair regression tasks due to too many possible combinations. Finding in a collection of n = 10 000 sentences the pair with the highest similarity requires with BERT n·(n−1)/2 = 49 995 000 inference computations. On a modern V100 GPU, this requires about 65 hours. Similar, finding which of the over 40 million existent questions of Quora is the most similar for a new question could be modeled as a pair-wise comparison with BERT, however, answering a single query would require over 50 hours.”
BERT는 두 문장을 하나의 입력으로 받는 encoder 구조인 ‘cross-encoder’로, 너무 많은 조합을 생성하기 때문에 적합하지 않을 수 있다고 언급합니다. \(n=10000\) 라면 그 combination인 \(n(n-1)/2=49995000\)번의 계산이 필요하기 때문에 비효율적이라고 말합니다.
“To alleviate this issue, we developed SBERT. The siamese network architecture enables that fixed-sized vectors for input sentences can be derived. Using a similarity measure like cosinesimilarity or Manhatten / Euclidean distance, semantically similar sentences can be found. These similarity measures can be performed extremely efficient on modern hardware, allowing SBERT to be used for semantic similarity search as well as for clustering. The complexity for finding the arXiv:1908.10084v1 [cs.CL] 27 Aug 2019 most similar sentence pair in a collection of 10,000 sentences is reduced from 65 hours with BERT to the computation of 10,000 sentence embeddings (~5 seconds with SBERT) and computing cosinesimilarity (~0.01 seconds). By using optimized index structures, finding the most similar Quora question can be reduced from 50 hours to a few milliseconds (Johnson et al., 2017).”
이를 해결하기 위해 ‘Siamese’ 네트워크를 가진 SBERT를 통해서 입력 문장에 대한 크기를 고정시키며 cosine similarity 나 Euclidean/Manhattan 거리를 통해 유사한 문장들을 찾을 수 있다고 합니다. ‘Siamese’ 네트워크를 통해 하드웨어 관점에서 효율적으로 수행될 수 있습니다.
“We fine-tune SBERT on NLI data, which creates sentence embeddings that significantly outperform other state-of-the-art sentence embedding methods like InferSent (Conneau et al., 2017) and Universal Sentence Encoder (Cer et al., 2018). On seven Semantic Textual Similarity (STS) tasks, SBERT achieves an improvement of 11.7 points compared to InferSent and 5.5 points compared to Universal Sentence Encoder. On SentEval (Conneau and Kiela, 2018), an evaluation toolkit for sentence embeddings, we achieve an improvement of 2.1 and 2.6 points, respectively.”
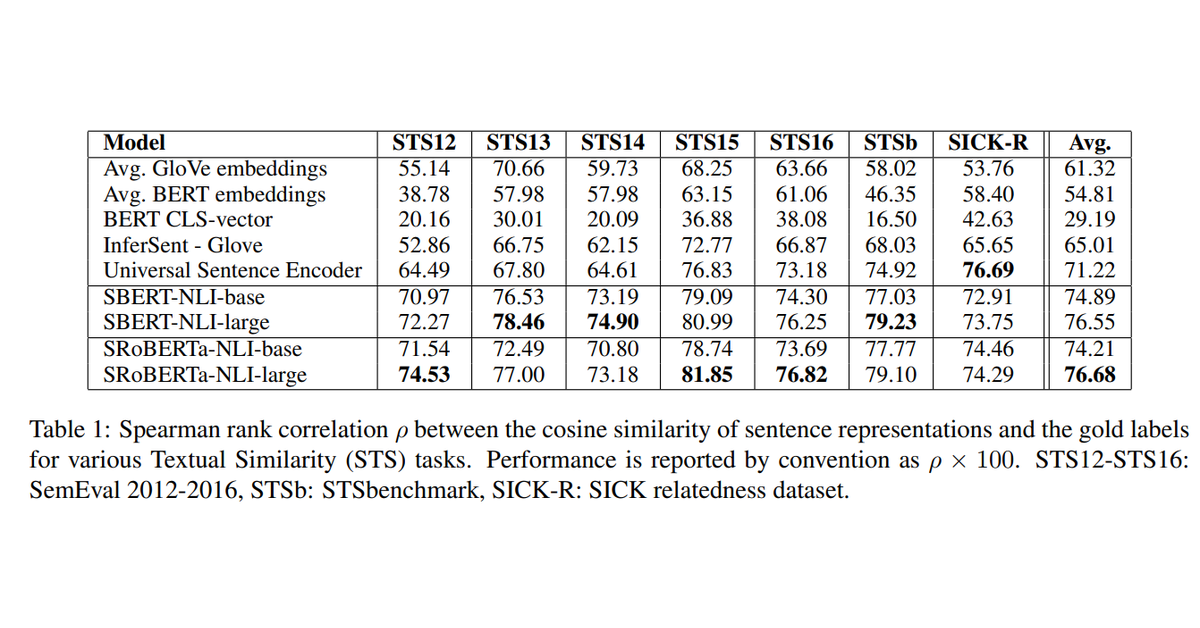
SBERT는 NLI 데이터로 fine-tunning 하였다고 합니다. 위 표와 같이 7개 STS task에서 InferSent 대비 11.7, Universal Sentence Encoder 대비 5.5 향상을 이루었습니다. 또 문장 임베딩을 평가하는 SentEval에서 각각 2.6 , 2.6 향상을 거두었다고 합니다.
2. Related Work
“A large disadvantage of the BERT network structure is that no independent sentence embed- dings are computed, which makes it difficult to de- rive sentence embeddings from BERT. To bypass this limitations, researchers passed single sen- tences through BERT and then derive a fixed sized vector by either averaging the outputs (similar to average word embeddings) or by using the output of the special CLS token (for example: May et al. (2019); Zhang et al. (2019); Qiao et al. (2019)). These two options are also provided by the popu- lar bert-as-a-service-repository3 . Up to our knowl- edge, there is so far no evaluation if these methods lead to useful sentence embeddings.”
이전 연구에 대한 내용입니다.
BERT 네트워크의 큰 단점인 단일한 문장을 임베딩한다는 점을 개선하기 위해, 단일한 문장을 BERT에 통과시킨 뒤 출력을 평균화 하는 방식(평균 단어 임베딩 방식)이나 CLS 토큰을 고정 크기 벡터 출력하는 방식이 제안하기도 하였습니다.
“Previous neural sentence embedding methods started the training from a random initialization. In this publication, we use the pre-trained BERT and RoBERTa network and only fine-tune it to yield useful sentence embeddings. This reduces significantly the needed training time: SBERT can be tuned in less than 20 minutes, while yielding better results than comparable sentence embed- ding methods.”
이전 다양한 문장 임베딩 연구에서는 random initial weight를 사용하였습니다. 저자들은 본 논문에서 pretrained 된 BERT나 RoBERTa 기반으로 이를 fine-tunning 하는 방식으로 진행합니다. 이를 통해 전체 Training 시간을 줄여 SBERT를 20분 이내에 학습시키고 다른 문장 임베딩 방법들과 비슷한 성능을 도출한다고 합니다.
3. Model
“SBERT adds a pooling operation to the output of BERT / RoBERTa to derive a fixed sized sen- tence embedding. We experiment with three pool- ing strategies: Using the output of the CLS-token, computing the mean of all output vectors (MEAN- strategy), and computing a max-over-time of the output vectors (MAX-strategy). The default config- uration is MEAN.”
앞서 언급된 것처럼 SBERT는 BERT나 RoBERTa 네트워크 기반에 Pooling 연산을 추가하여 임베딩합니다. 본 연구에서는 CLS 토큰의 출력, 모든 출력 벡터의 평균, 출력 벡터들 사이에서의 최대값을 활용하는 등 3가지 방식을 실험합니다. 기본적으로는 모든 출력 벡터의 평균 방식인 ‘MEAN-strategy’로 진행됩니다.
“In order to fine-tune BERT / RoBERTa, we cre- ate siamese and triplet networks (Schroff et al., 2015) to update the weights such that the produced sentence embeddings are semantically meaningful and can be compared with cosine-similarity.”
SBERT의 핵심 요소로 ‘siamese’, ‘triplet nerworks’ 활용한다는 내용입니다.
“The network structure depends on the availabletraining data. We experiment with the following structures and objective functions.”
원하는 task에 따라 구제척인 네트워크 구조와 objective function이 달라집니다.
“Classification Objective Function. We con- catenate the sentence embeddings u and v with the element-wise difference |u − v| and multiply it with the trainable weight Wt ∈ R3n×k : o = softmax(Wt (u, v, |u − v|)) where n is the dimension of the sentence em- beddings and k the number of labels. We optimize cross-entropy loss. This structure is depicted in Figure 1.”
분류가 목적이라면, 문장을 임베딩 한 값 \(u,\ v\)와 임베딩 값의 차이 \(|u-v|\)를 concat하여 사용합니다.
\[o = softmax(W_t(u, v, |u-v|))\]“Regression Objective Function. The cosine- similarity between the two sentence embeddings u and v is computed (Figure 2). We use mean- squared-error loss as the objective function.”
코사인 유사도를 활용하여 두 문장 유사도를 구한다면, 두 문장 임베딩 \(u,\ v\)를 활용하고 MSE를 손실함수로 사용합니다,
“Triplet Objective Function. Given an anchor sentence a, a positive sentence p, and a negative sentence n, triplet loss tunes the network such that the distance between a and p is smaller than the distance between a and n. Mathematically, we minimize the following loss function: \(max(||s_{a} - s_{p} || - ||s_{a} - s_{n} || + \epsilon, 0)\) with s_{x} the sentence embedding for a/n/p, || · || a distance metric and margin \(\epsilon\). Margin \(\epsilon\) ensures that \(s_{p}\) is at least \(\epsilon\) closer to sa than \(s_{n}\) . As metric we use Euclidean distance and we set \(\epsilon = 1\) in our experiments.”
유클리드 거리 방식으로 측정한다면, ‘Triplet Obejective Function’을 활용하게 됩니다. 이때 anchor sentence를 a, positive sentence를 p, negative sentence를 n으로 하며 a,p의 거리를 a,n으로의 거리보다 작도록 학습하면 됩니다.
\[max(||s_{a} - s_{p} || - ||s_{a} - s_{n} || + \epsilon, 0)\]\(s_{x}\)는 a/n/p에 대한 문장 임베딩 값이고, margin으로 표현한 \(\epsilon\)은 \(s_{p}\)가 \(\epsilon\) 만큼은 \(s_{a}\)에 가깝게 보완하는 역할을 합니다.
3.1 Training Details
“We train SBERT on the combination of the SNLI (Bowman et al., 2015) and the Multi-Genre NLI(Williams et al., 2018) dataset. The SNLI is a col- lection of 570,000 sentence pairs annotated with the labels contradiction, eintailment, and neu- tral. MultiNLI contains 430,000 sentence pairs and covers a range of genres of spoken and written text. We fine-tune SBERT with a 3-way softmax- classifier objective function for one epoch. We used a batch-size of 16, Adam optimizer with learning rate 2e−5, and a linear learning rate warm-up over 10% of the training data. Our de- fault pooling strategy is MEAN”
contradiction, entailment, neutral 레이블로 이루어진 SNLI 데이터셋과 다양한 장르의 문장 쌍 데이터인 MultiNLI를 통해 학습했다고 합니다. softmax- classifier objective을 objective function으로 사용하였고 1 epoch, 16 batch-size, adam optimizer 2e-5, linear warm-up으로 fine-tunning하였으며 pooling은 앞서 언급된 ‘MEAN-strategy’입니다.
4. Evaluation - Semantic Textual Similarity
4.1 Unsupervised STS
“The results shows that directly using the output of BERT leads to rather poor performances. Averaging the BERT embeddings achieves an average correlation of only 54.81, and using the CLStoken output only achieves an average correlation of 29.19. Both are worse than computing average GloVe embeddings.”
Table 1에서 제시한 것과 같이 BERT의 임베딩 벡터를 평균화하는 방식은 54.81이며, CLS 토큰을 활용하는 방식은 29.19 였습니다. 이 두 방식 모두 Glove의 평균 임베딩 보다 성능이 떨어집니다.
“Using the described siamese network structure and fine-tuning mechanism substantially improves the correlation, outperforming both InferSent and Universal Sentence Encoder substantially. The only dataset where SBERT performs worse than Universal Sentence Encoder is SICK-R. Universal Sentence Encoder was trained on various datasets, including news, question-answer pages and discussion forums, which appears to be more suitable to the data of SICK-R. In contrast, SBERT was pre-trained only on Wikipedia (via BERT) and on NLI data.”
“While RoBERTa was able to improve the performance for several supervised tasks, we only observe minor difference between SBERT and SRoBERTa for generating sentence embeddings.”
SBERT가 Universal Sentence Encoder보다 성능이 떨어지는 유일한 데이터셋은 SICK-R입니다. RoBERTa가 여러 지도 학습 태스크에서 성능을 향상시킬 수 있었지만, 문장 임베딩 생성에 있어서는 SBERT와 SRoBERTa 간에 미미한 차이만 있습니다.
4.2 Supervised STS
“The STS benchmark (STSb) (Cer et al., 2017) provides is a popular dataset to evaluate supervised STS systems. The data includes 8,628 sentence pairs from the three categories captions, news, and forums. It is divided into train (5,749), dev (1,500) and test (1,379).”
STS benchmark는 지도 학습 STS을 평가하기 위한 데이터셋이며, 이 데이터는 caption, 뉴스, forum의 세 가지 카테고리에서 가져온 8,628개의 문장 쌍을 포함합니다. 이는 train 세트(5,749), dev 세트(1,500), 그리고 test 세트(1,379)로 나뉩니다.
“We use the training set to fine-tune SBERT using the regression objective function. At prediction time, we compute the cosine-similarity between the sentence embeddings. All systems are trained with 10 random seeds to counter variances (Reimers and Gurevych, 2018).”
regression objective function를 사용하여 SBERT를 fine-tune하기 위해 훈련 세트를 사용합니다. 예측 시에 문장 임베딩 간의 코사인 유사도를 계산합니다. 모든 결과는 편차를 상쇄하기 위해 10개의 랜덤 시드로 훈련되었다고 합니다.
“The results are depicted in Table 2. We experimented with two setups: Only training on STSb, and first training on NLI, then training on STSb. We observe that the later strategy leads to a slight improvement of 1-2 points. This two-step approach had an especially large impact for the BERT cross-encoder, which improved the performance by 3-4 points. We do not observe a significant difference between BERT and RoBERTa”
Table 2에 나온 결과와 같이 STS 데이터셋으로만 학습시키는 방식과 NLI 데이터셋 학습 후 STS 데이터셋으로 학습시키는 방식으로 실험했습니다. 후자의 방법이 1~2 포인트 정도 성능 향상을 가져왔습니다. 특히 후자의 방법은 BERT cross-encoder를 통해 3~4 포인트 정도 향상시켰다고 합니다.
4.3 Argument Facet Similarity
“We evaluate SBERT on the Argument Facet Similarity (AFS) corpus by Misra et al. (2016). The AFS corpus annotated 6,000 sentential argument pairs from social media dialogs on three controversial topics: gun control, gay marriage, and death penalty. The data was annotated on a scale from 0 (“different topic”) to 5 (“completely equivalent”). The similarity notion in the AFS corpus is fairly different to the similarity notion in the STS datasets from SemEval. STS data is usually descriptive, while AFS data are argumentative excerpts from dialogs. To be considered similar, arguments must not only make similar claims, but also provide a similar reasoning. Further, the lexical gap between the sentences in AFS is much larger. Hence, simple unsupervised methods as well as state-of-the-art STS systems perform badly on this dataset (Reimers et al., 2019).”
또한 Argument Facet Similarity(AFS) 말뭉치에서 SBERT를 평가했습니다. AFS corpus는 총기 규제, 동성 결혼, 사형 제도라는 세 가지 논쟁이 있을 만한 주제에 관한 대화에서 6,000개의 문장 단위 argument 쌍에 주석을 달았습니다.
“We evaluate SBERT on this dataset in two scenarios: 1) As proposed by Misra et al., we evaluate SBERT using 10-fold cross-validation. A drawback of this evaluation setup is that it is not clear how well approaches generalize to different topics. Hence, 2) we evaluate SBERT in a cross-topic setup. Two topics serve for training and the approach is evaluated on the left-out topic. We repeat this for all three topics and average the results.”
AFS 데이터셋을 통해 두가지 시나리오로 실험했다고 합니다. AFS 데이터셋에는 총기 규제, 동성 결혼, 사형 제도라는 주제에 대한 문장쌍이 있습니다. 첫번째 시나리오로 9개의 fold로 train and 1개 fold로 테스트하는 방식이 있고 두번째 시나리오로는 세가지 주제 중 두가지 주제로만 학습하고 나머지 한가지 주제는 테스트로만 사용하는 방식입니다. 두번째 방법의 장점은 새로운 주제에 대해 일반화 성능을 갖출 수 있다는 점입니다.
“Unsupervised methods like tf-idf, average GloVe embeddings or InferSent perform rather badly on this dataset with low scores. Training SBERT in the 10-fold cross-validation setup gives a performance that is nearly on-par with BERT.”
Table 3과 같이 tf-idf, Glove, InferSent 방식들은 낮은 점수를 보이며, 10-fold-cross-validation의 SBERT를 활용하면 BERT와 유사한 성능을 얻을 수 있습니다.
“However, in the cross-topic evaluation, we observe a performance drop of SBERT by about 7 points Spearman correlation. To be considered similar, arguments should address the same claims and provide the same reasoning. BERT is able to use attention to compare directly both sentences (e.g. word-by-word comparison), while SBERT must map individual sentences from an unseen topic to a vector space such that arguments with similar claims and reasons are close. This is a much more challenging task, which appears to require more than just two topics for training to work on-par with BERT.”
하지만 cross-topic 평가에서는 SBERT의 성능이 Spearman 상관관계에서 7포인트 정도 하락하였고, 이러한 원인으로 BERT는 attention을 사용하여 두 문장을 직접 비교할 수 있지만, SBERT는 보지 못한 주제의 개별 문장을 벡터 공간에 매핑하여 유사한 주장과 이유를 가진 argument가 가깝게 위치하도록 해야 합니다. 이는 SBERT에게는 어려운 task로 훨씬 더 많은 데이터가 필요할 수 있다고 합니다.
4.4 Wikipedia Sections Distinction
“Dor et al. (2018) use Wikipedia to create a thematically fine-grained train, dev and test set for sentence embeddings methods. Wikipedia articles are separated into distinct sections focusing on certain aspects. Dor et al. assume that sentences in the same section are thematically closer than sentences in different sections. They use this to create a large dataset of weakly labeled sentence triplets: The anchor and the positive example come from the same section, while the negative example comes from a different section of the same article. For example, from the Alice Arnold article: Anchor: Arnold joined the BBC Radio Drama Company in 1988., positive: Arnold gained media attention in May 2012., negative: Balding and Arnold are keen amateur golfers.”
Wikipedia article들은 특정 분야에 관한 각각의 section으로 나뉘어져 있습니다. 같은 section 내의 문장들이 다른 section의 문장들보다 주제가 더 가깝다고 가정하고, 이를 활용하여 anchor와 positive 예시는 동일 section에서 가져오고, negative 예시는 같은 article의 다른 section에서 가져옵니다.
“We use the dataset from Dor et al. We use the Triplet Objective, train SBERT for one epoch on the about 1.8 Million training triplets and evaluate it on the 222,957 test triplets. Test triplets are from a distinct set of Wikipedia articles. As evaluation metric, we use accuracy: Is the positive example closer to the anchor than the negative example? Results are presented in Table 4. Dor et al. finetuned a BiLSTM architecture with triplet loss to derive sentence embeddings for this dataset. As the table shows, SBERT clearly outperforms the BiLSTM approach by Dor et al. “
triplet objective를 사용하여 대략 180만 개의 훈련 triplet에 대해 SBERT를 1 epoch 동안 훈련시켰고 222,957개의 test triplet에서 평가했습니다. test triplet은 Wikipedia article 데이터로 가져온 것이며 평가 지표는 accuracy를 사용합니다. 결과는 위 Table 4에 있습니다.
5. Evaluation - SentEval
“We compare the SBERT sentence embeddings to other sentence embeddings methods on the following seven SentEval transfer tasks: • MR: Sentiment prediction for movie reviews snippets on a five start scale (Pang and Lee, 2005). • CR: Sentiment prediction of customer product reviews (Hu and Liu, 2004). • SUBJ: Subjectivity prediction of sentences from movie reviews and plot summaries (Pang and Lee, 2004). • MPQA: Phrase level opinion polarity classification from newswire (Wiebe et al., 2005). • SST: Stanford Sentiment Treebank with binary labels (Socher et al., 2013). • TREC: Fine grained question-type classification from TREC (Li and Roth, 2002). • MRPC: Microsoft Research Paraphrase Corpus from parallel news sources (Dolan et al., 2004). “
저자들은 7가지 SentEval transfer task에서 SBERT 문장 임베딩을 다른 문장 임베딩 방법들과 비교합니다.
- MR: 영화 리뷰에 대한 5점 만점의 감성 예측
- CR: 제품 리뷰의 감성 예측
- SUBJ: 영화 리뷰와 줄거리 요약에서의 문장 주관성 예측
- MPQA: 뉴스 기사에서의 구문 수준 분류
- SST: 이진 레이블이 있는 Stanford Sentiment Treebank
- TREC: TREC의 세분화된 질문 유형 분류
- MRPC: 뉴스 소스에서 얻은 Microsoft Research Paraphrase Corpus
“The results can be found in Table 5. SBERT is able to achieve the best performance in 5 out of 7 tasks. The average performance increases by about 2 percentage points compared to InferSent as well as the Universal Sentence Encoder. Even though transfer learning is not the purpose of SBERT, it outperforms other state-of-the-art sentence embeddings methods on this task.”
Table 5에 나와있듯이, SBERT는 7개 task 중 5개에서 최고의 성능을 달성하였습니다. 평균 성능은 InferSent와 Universal Sentence Encoder에 비해 약 2 퍼센트 포인트 증가했고, transfer learning이 SBERT의 본 목적이 아니지만, 이 task에서 다른 sota 문장 임베딩 방법들을 능가하는 성능을 보여주었습니다.
“It appears that the sentence embeddings from SBERT capture well sentiment information: We observe large improvements for all sentiment tasks (MR, CR, and SST) from SentEval in comparison to InferSent and Universal Sentence Encoder. The only dataset where SBERT is significantly worse than Universal Sentence Encoder is the TREC dataset. Universal Sentence Encoder was pre-trained on question-answering data, which appears to be beneficial for the question-type classification task of the TREC dataset.”
SBERT의 문장 임베딩이 감성 정보를 잘 이해하는 것으로 나타납니다. SentEval의 모든 감성 task(MR, CR, SST)에서 InferSent와 Universal Sentence Encoder에 비해 큰 성능 향상을 보였습니다. 단, SBERT가 Universal Sentence Encoder보다 현저히 성능이 떨어지는 유일한 데이터셋은 TREC 데이터셋인데 이는 Universal Sentence Encoder는 질문-답변 데이터로 사전 훈련되있고 TREC 데이터셋의 질문 유형 분류 task에 유리하기 때문이라고 말합니다.
“We conclude that average BERT embeddings / CLS-token output from BERT return sentence embeddings that are infeasible to be used with cosinesimilarity or with Manhatten / Euclidean distance. For transfer learning, they yield slightly worse results than InferSent or Universal Sentence Encoder. However, using the described fine-tuning setup with a siamese network structure on NLI datasets yields sentence embeddings that achieve a new state-of-the-art for the SentEval toolkit.”
저자들은 평균 BERT 임베딩과 BERT의 CLS 토큰 출력이 cosine 유사도나 Manhattan/Euclidean 거리와 함께 사용하기에는 적합하지 않은 문장 임베딩을 출력한다고 결론을 내립니다. transfer learning의 경우, 이는 InferSent나 Universal Sentence Encoder보다 약간은 더 나쁜 성능을 보입니다. 그러나 NLI 데이터셋에서 siamese 네트워크 구조를 가진 설명된 fine-tuning 설정을 사용하면 SentEval 툴킷에서 새로운 sota 성능을 달성하는 문장 임베딩을 얻을 수 있습니다.
6. Ablation Study
“We evaluated different pooling strategies (MEAN, MAX, and CLS). For the classification objective function, we evaluate different concatenation methods. For each possible configuration, we train SBERT with 10 different random seeds and average the performances.”
저자들은 여러 pooling 방식(MEAN, MAX, CLS)을 평가했습니다. classification objective function 에서는 여러 concatenation 방법을 평가했습니다
“The objective function (classification vs. regression) depends on the annotated dataset. For the classification objective function, we train SBERTbase on the SNLI and the Multi-NLI dataset. For the regression objective function, we train on the training set of the STS benchmark dataset. Performances are measured on the development split of the STS benchmark dataset. Results are shown in Table 6.”
concatenation 방식은 MEAN pooling 방식만 사용
classification objective function(entailment, contradiction, neutral with cross-entropy)의 경우에 SNLI와 Multi-NLI 데이터셋에서 SBERT-base를 훈련시켰고, regression objective function(0~5 with MSE)의 경우에는 STS 데이터셋의 train 세트에서 모델을 훈련시켰습니다. 결과는 위 Table 6에 나와있습니다.
“When trained with the classification objective function on NLI data, the pooling strategy has a rather minor impact. The impact of the concate- nation mode is much larger. InferSent (Conneauet al., 2017) and Universal Sentence Encoder (Cer et al., 2018) both use (u, v, |u − v|, u ∗ v) as input for a softmax classifier. However, in our architec- ture, adding the element-wise u ∗ v decreased the performance.”
NLI 데이터에서 classification objective function로 훈련할 때, pooling 방식은 미미한 영향을 미칩니다. concatenation의 영향이 훨씬 더 크다고 합니다. 또한 elemental wise한 \(u\ *\ v\)를 추가하면 성능이 감소했습니다.
“The most important component is the elementwise difference |u − v|. Note, that the concatenation mode is only relevant for training the softmax classifier. At inference, when predicting similarities for the STS benchmark dataset, only the sentence embeddings u and v are used in combination with cosine-similarity. The element-wise difference measures the distance between the dimensions of the two sentence embeddings, ensuring that similar pairs are closer and dissimilar pairs are further apart.”
가장 중요했던 요소는 element-wise difference인 \(|u-v|\)입니다. concatenation은 softmax를 훈련시킬 때만 관련이 있으며, 추론 단계에서 STS 데이터셋의 유사도를 예측할 때는 문장 임베딩 \(u\)와 \(v\)만 코사인 유사도와 함께 사용됩니다. elemental wise에서의 차이는 두 문장 임베딩의 차원 간 거리를 측정하여 유사한 문장 쌍들은 더 가깝게, 유사하지 않은 쌍은 더 멀리 위치하도록 보장하는 역할을 합니다.
“When trained with the regression objective function, we observe that the pooling strategy has a large impact. There, the MAX strategy perform significantly worse than MEAN or CLS-token strategy. This is in contrast to (Conneau et al., 2017), who found it beneficial for the BiLSTM-layer of InferSent to use MAX instead of MEAN pooling. “
regression objective function에서는 pooling 방식에 따라 큰 영향을 미친다고 합니다.
7. Computational Efficiency
“Sentence embeddings need potentially be computed for Millions of sentences, hence, a high computation speed is desired. In this section, we compare SBERT to average GloVe embeddings, InferSent (Conneau et al., 2017), and Universal Sentence Encoder (Cer et al., 2018). For our comparison we use the sentences from the STS benchmark (Cer et al., 2017). We compute average GloVe embeddings using a simple for-loop with python dictionary lookups and NumPy. InferSent4 is based on PyTorch. For Universal Sentence Encoder, we use the TensorFlow Hub version5 , which is based on TensorFlow. SBERT is based on PyTorch. For improved computation of sentence embeddings, we implemented a smart batching strategy: Sentences with similar lengths are grouped together and are only padded to the longest element in a mini-batch. This drastically reduces computational overhead from padding tokens.”
문장 임베딩은 수백만 개의 문장에 대해 계산되어야 하므로, 높은 계산 속도가 요구됩니다. 해당 section에서는 이를 비교합니다. Glove는 파이썬 딕셔너리 lookup, numpy를 사용하고, InferSent는 Pytorch, Universal Sentence Encoder는 Tensorflow, SBERT는 Pytorch 기반으로 계산합니다. smart batch 방식으로, 유사한 길이 문장들을 묶어 그룹화하고 mini-batch 내에서 가장 긴 요소까지 padding 했다고 합니다. 이로 인해 연산 overhead를 줄일 수 있다고 합니다.
“On CPU, InferSent is about 65% faster than SBERT. This is due to the much simpler network architecture. InferSent uses a single BiLSTM layer, while BERT uses 12 stacked transformer layers. However, an advantage of transformer networks is the computational efficiency on GPUs. There, SBERT with smart batching is about 9% faster than InferSent and about 55% faster than Universal Sentence Encoder. Smart batching achieves a speed-up of 89% on CPU and 48% on GPU. Average GloVe embeddings is obviously by a large margin the fastest method to compute sentence embeddings.”
CPU에서는 InferSent가 SBERT보다 약 65% 더 빠르게 나옵니다. 이는 InferSent가 더 단순한 아키텍처이기 때문입니다. InferSent는 단일 BiLSTM 레이어를 사용하는 반면, BERT는 12개의 transformer 레이어로 이루어집니다. 그러나 transformer의 장점은 GPU에서의 계산 효율성입니다. GPU에서는 smart batching을 적용한 SBERT가 InferSent보다 약 9% 더 빠르고 Universal Sentence Encoder보다 약 55% 더 빠릅니다. smart batching은 CPU에서 89%, GPU에서 48%의 속도 향상을 달성합니다. 당연히 평균 GloVe 임베딩은 문장 임베딩을 계산하는 가장 빠른 방법으로, 다른 방법들보다 큰 차이로 빠르게 나옵니다.
8. Conclusion
“We showed that BERT out-of-the-box maps sentences to a vector space that is rather unsuitable to be used with common similarity measures like cosine-similarity. The performance for seven STS tasks was below the performance of average GloVe embeddings”
저자들은 BERT가 기본적으로 out-of-the-box 문장을 cosine 유사도와 같은 일반적인 유사도 측정 방식과 함께 사용하기에 적합하지 않은 벡터로 나타낸 것을 보여주었다고 합니다. 7개의 STS task에 대한 성능은 평균 GloVe 임베딩의 성능보다도 낮았습니다.
“To overcome this shortcoming, we presented Sentence-BERT (SBERT). SBERT fine-tunes BERT in a siamese / triplet network architecture. We evaluated the quality on various common benchmarks, where it could achieve a significant improvement over state-of-the-art sentence embeddings methods. Replacing BERT with RoBERTa did not yield a significant improvement in our experiments.”
이를 위해, Sentence-BERT(SBERT)를 제안했습니다. SBERT는 siamese/triplet 네트워크에서 BERT를 fine-tune하게 되었고, 기존 sota 임베딩 방법들에 비해 큰 성능 향상을 달성할 수 있었습니다.
“SBERT is computationally efficient. On a GPU, it is about 9% faster than InferSent and about 55% faster than Universal Sentence Encoder. SBERT can be used for tasks which are computationally not feasible to be modeled with BERT. For example, clustering of 10,000 sentences with hierarchical clustering requires with BERT about 65 hours, as around 50 Million sentence combinations must be computed. With SBERT, we were able to reduce the effort to about 5 seconds.”
SBERT는 연산도 효율적입니다. GPU에서 InferSent보다 약 9% 더 빠르고 Universal Sentence Encoder보다 약 55% 더 빠릅니다. SBERT는 BERT로 활용할 때는 연산량이 극히 많은 작업에 대안으로써 사용될 수도 있습니다. 예시로 hierarchical clustering에서는 BERT로는 약 50백만 개의 문장들의 조합을 연산하기 때문에 약 65시간이 소요되지만 SBERT는 약 5초로 줄일 수 있습니다.