RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa 논문을 꼼꼼히 살펴봅시다.
Source: https://arxiv.org/pdf/1907.11692
RoBERTa
RoBERTa: A Robustly Optimized BERT Pretraining Approach 내용을 자세히 살펴보고 중요한 내용를 정리합니다.
Abstract
[원문]
“Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al. , 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.”
저자들은 BERT를 Pretrain 하는데 있어서 undertrained 되었다고 언급하며 더욱 개선된 학습 방법으로 학습하여 GLUE, RACE, SQuAD 벤치마크에서 최고 성능을 달성한 연구 결과를 제시합니다.
1. Introduction
“Self-training methods such as ELMo (Peters et al. , 2018), GPT (Radford et al. , 2018), BERT (Devlin et al. , 2019), XLM (Lample and Conneau , 2019), and XLNet (Yang et al. , 2019) have brought significant performance gains, but it can be challenging to determine which aspects of the methods contribute the most. Training is computationally expensive, limiting the amount of tuning that can be done, and is often done with private training data of varying sizes, limiting our ability to measure the effects of the modeling advances. “
과소학습된 기존 BERT에서 더욱 큰 batch-size/datasets, NSP(Next Sentence Prediction) 방식 제거, 더욱 긴 sequence 길이, dynamic masking pattern 학습 방식을 적용하여 성능을 끌어올린다고 언급합니다.
“When controlling for training data, our improved training procedure improves upon the published BERT results on both GLUE and SQuAD. When trained for longer over additional data, our model achieves a score of 88.5 on the public GLUE leaderboard, matching the 88.4 reported by Yang et al. (2019). Our model establishes a new state-of-the-art on 4/9 of the GLUE tasks: MNLI, QNLI, RTE and STS-B. We also match state-of-the-art results on SQuAD and RACE. Overall, we re-establish that BERT’s masked language model training objective is competitive with other recently proposed training objectives such as perturbed autoregressive language modeling (Yang et al., 2019).2”
동일한 학습 데이터 기준으로 BERT 대비 GLUE, SQuAD 벤치마크에서 성능 향상을 보였고, GLUE의 9개 task에서 MNLI, QNLI, RTE, STS-B task에서 새로운 sota 성능을 발휘하였다고 합니다.
2. Background
해당 section에서는 기존 BERT 모델에 대한 배경 설명 부분으로 아래와 같이 요약됩니다.
- 두 segment를 연결한 입력과 특수 토큰([CLS], [SEP], [EOS])을 사용
- transformer 기반 (L개 layer, A개 attention head, H 차원)
- MLM: 토큰의 15%를 마스킹하고 예측
- NSP: 두 segment가 연속적인지 예측하는 이진 분류
- Adam 사용
- 학습 데이터는 BOOKCORPUS와 영어 WIKIPEDIA (총 16GB)
- 1,000,000번 업데이트, batch-size 256, 최대 sequence 512 tokens
3. Experimental Setup
BERT와 유사한(논문에는 replication이라고 표현) 연구를 위한 실험 설정에 대한 내용입니다.
3.1 Implementation
- Adam \(\epsilon\) 값이 성능에 큰 영향을 미치므로 큰 batch에서는 \(\beta_{2} = 0.98\)로 설정
- 512 token 길이의 시퀀스만 학습
3.2 Data
- 총 160GB 이상
- BOOKCORPUS(영어 WIKIPEDIA, 16GB), CC-NEWS(영어 뉴스 기사, 76GB), OPENWEBTEXT(Reddit, 38GB), STORIES(CommonCrawl 데이터의 하위 집합, 31GB)
3.3 Evaluation
- 세 가지 벤치마크를 사용하여 사전학습된 모델을 downstream 작업에서 평가합니다.
- GLUE: 단일 문장 분류 또는 문장 쌍 분류 작업으로 구성
- SQuAD: 문맥에서 관련 스팬(span)을 추출하여 질문에 답하는 Stanford 질문 응답 데이터셋
- RACE: 중국의 영어 시험에서 수집된 8,000개 이상의 지문과 거의 100,000개의 독해 데이터셋, 네 가지 옵션 중에서 하나의 정답을 선택
4. Training Procedure Analysis
“This section explores and quantifies which choices are important for successfully pretraining BERT models. We keep the model architecture fixed.7 Specifically, we begin by training BERT models with the same configuration as BERTBASE (L = 12, H = 768, A = 12, 110M params).”
기존 BERT BASE와 동일한 구성(L = 12, H = 768, A = 12, 110M 파라미터)으로 BERT 모델 학습합니다.
4.1 Static vs. Dynamic Masking
“As discussed in Section 2, BERT relies on randomly masking and predicting tokens. The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training. We compare this strategy with dynamic masking where we generate the masking pattern every time we feed a sequence to the model. This becomes crucial when pretraining for more steps or with larger datasets. “
기존 BERT는 masking을 한 번 수행하여 static masking를 생성했습니다. 매 epoch마다 동일한 mask를 사용하는 것을 피하기 위해, 10번 복제되어 40 epoch의 학습 기간 동안 각 sequence가 10가지 다른 방식으로 마스킹되도록 했습니다.
“Results Table 1 compares the published BERTBASE results from Devlin et al. (2019) to our reimplementation with either static or dynamic masking. We find that our reimplementation with static masking performs similar to the original BERT model, and dynamic masking is comparable or slightly better than static masking. Given these results and the additional efficiency benefits of dynamic masking, we use dynamic masking in the remainder of the experiments.”
dynamic masking은 static masking과 비슷하거나 약간 더 나은 성능을 보입니다. 저자들은 이후 실험에서도 dynamic masking을 사용합니다.
4.2 Model Input Format and Next Sentence Prediction
“In the original BERT pretraining procedure, the model observes two concatenated document segments, which are either sampled contiguously from the same document (with p = 0.5) or from distinct documents. In addition to the masked language modeling objective, the model is trained to predict whether the observed document segments come from the same or distinct documents via an auxiliary Next Sentence Prediction (NSP) loss. The NSP loss was hypothesized to be an important factor in training the original BERT model. Devlin et al. (2019) observe that removing NSP hurts performance, with significant performance degradation on QNLI, MNLI, and SQuAD 1.1. However, some recent work has questioned the necessity of the NSP loss (Lample and Conneau, 2019; Yang et al., 2019; Joshi et al., 2019). To better understand this discrepancy, we compare several alternative training formats:”
Devlin et al.(2019) 연구에 의하면 NSP를 제거했을 때 QNLI, MNLI 및 SQuAD 1.1에서 성능 저하가 있다고 관찰했습니다. 하지만 본 논문에서는 이에 대한 다른 대안을 제시합니다.
위 Table 2에서
- SEGMENT-PAIR+NSP: 기존 BERT 입력 형식, 각 입력은 segment 쌍, 각 segment는 여러 문장 포함, 총 결합 길이는 512 토큰
- SENTENCE-PAIR+NSP: 각 입력은 한 문서의 연속적인 부분에서 샘플링 or 별도의 문서에서 샘플링된 자연 문장 쌍
- FULL-SENTENCES: 각 입력은 하나 이상의 문서에서 연속적으로 샘플링된 전체 문장, 최대 512 token , NSP 제거, 문서 사이에 sep token
- DOC-SENTENCES: 입력은 FULL-SENTENCES와 유사, 문서 경계 overlap X
“Results Table 2 shows results for the four different settings. We first compare the original SEGMENT-PAIR input format from Devlin et al. (2019) to the SENTENCE-PAIR format; both formats retain the NSP loss, but the latter uses single sentences. We find that using individual sentences hurts performance on downstream tasks, which we hypothesize is because the model is not able to learn long-range dependencies. “
NSP 없이 학습하는 방식과 단일 문서의 텍스트로 학습하는 방식(DOC-SENTENCES)을 비교한 내용입니다. 이 설정이 원래 발표된 BERT BASE 결과보다 더 좋은 성능을 보이며, Devlin et al.(2019)의 기존 주장과는 달리 NSP를 제거하는 것이 downstream 작업 성능과 일치하거나 약간 향상시킨다는 것을 발견했습니다. 또한 단일 문서 시퀀스(DOC-SENTENCES)가 다중 문서 시퀀스(FULL-SENTENCES)보다 약간 우수하지만 가변적인 batch size를 유발하기 때문에 이후 실험에서는 FULL-SENTENCES를 사용했다고 합니다.
4.3 Training with large batches
“Past work in Neural Machine Translation has shown that training with very large mini-batches can both improve optimization speed and end-task performance when the learning rate is increased appropriately (Ott et al., 2018). Recent work has shown that BERT is also amenable to large batch training (You et al., 2019). Devlin et al. (2019) originally trained BERTBASE for 1M steps with a batch size of 256 sequences. This is equivalent in computational cost, via gradient accumulation, to training for 125K steps with a batch size of 2K sequences, or for 31K steps with a batch size of 8K. “
기계 번역 분야의 이전 연구에서 큰 mini-batch로 학습할 때 lr을 적절히 증가시키면 최적화 속도와 성능 모두를 향상시킬 수 있다는 것을 보여주었고, 기존 BERT Base에서 256 batch size 로 1M step 동안 학습한것과 연산 측면에서 유사한 2K batch size로 125K step/ 8K의 batch size로 31K step 동안 학습하였고 결과는 아래 Table 3와 같습니다.
하이퍼파라미터 조건별 ppl과 NLI/SST 성능을 보여줍니다.
4.4 Text Encoding
“BPE vocabulary sizes typically range from 10K-100K subword units. However, unicode characters can account for a sizeable portion of this vocabulary when modeling large and diverse corpora, such as the ones considered in this work. Radford et al. (2019) introduce a clever implementation of BPE that uses bytes instead of unicode characters as the base subword units. Using bytes makes it possible to learn a subword vocabulary of a modest size (50K units) that can still encode any input text without introducing any “unknown” tokens. “
Byte-Pair Encoding (BPE) 인코딩을 사용하여 unknown-token을 포함한 모든 입력을 인코딩할 수 있는 크기(50K 단위)의 subword를 학습하는 것이 가능하게 하였습니다.
“Early experiments revealed only slight differences between these encodings, with the Radford et al. (2019) BPE achieving slightly worse end-task performance on some tasks. Nevertheless, we believe the advantages of a universal encoding scheme outweighs the minor degredation in performance and use this encoding in the remainder of our experiments. A more detailed comparison of these encodings is left to future work.”
BPE가 일부 task에서 약간 더 낮은 성능 보였지만, BPE의 범용적인 특징이 더 장점있다고 생각해서 실험에서는 이 인코딩 방식을 사용했다고 합니다.
5. RoBERTa
“In the previous section we propose modifications to the BERT pretraining procedure that improve end-task performance. We now aggregate these improvements and evaluate their combined impact. We call this configuration RoBERTa for Robustly optimized BERT approach. Specifically, RoBERTa is trained with dynamic masking (Section 4.1), FULL-SENTENCES without NSP loss (Section 4.2), large mini-batches (Section 4.3) and a larger byte-level BPE (Section 4.4). “
dynamic masking, NSP를 제거한 FULL-SENTENCES, 대규모 데이터셋, BPE 인코딩을 활용한 최적화된 BERT 기법인 ‘RoBERTa’를 명명합니다.
“To help disentangle the importance of these factors from other modeling choices (e.g., the pretraining objective), we begin by training RoBERTa following the BERTLARGE architecture (L = 24, H = 1024, A = 16, 355M parameters). We pretrain for 100K steps over a comparable BOOKCORPUS plus WIKIPEDIA dataset as was used in Devlin et al. (2019). We pretrain our model using 1024 V100 GPUs for approximately one day.”
저자들은 BERT LARGE (L = 24, H = 1024, A = 16, 355M 파라미터)를 기반으로 하고 BOOKCORPUS와 WIKIPEDIA 데이터셋으로 100K step 동안 pre-trained 했습니다.
“Results We present our results in Table 4. When controlling for training data, we observe that RoBERTa provides a large improvement over the originally reported BERTLARGE results, reaffirming the importance of the design choices we explored in Section 4.”
그 결과로 위 Table 4와 같이 BERT LARGE에 비해 큰 성능 향상을 보였습니다.
“Next, we combine this data with the three additional datasets described in Section 3.2. We train RoBERTa over the combined data with the same number of training steps as before (100K). In total, we pretrain over 160GB of text. We observe further improvements in performance across all downstream tasks, validating the importance of data size and diversity in pretraining.9”
총 160GB 텍스트로 pre-trained 했을 때, 모든 downstream task에서 향상을 보였기 때문에 사전학습 단계에서 데이터셋의 크기/다양성의 중요성이 드러나는 지표라고 볼 수 있습니다.
“Finally, we pretrain RoBERTa for significantly longer, increasing the number of pretraining steps from 100K to 300K, and then further to 500K. We again observe significant gains in downstream task performance, and the 300K and 500K step models outperform XLNetLARGE across most tasks. We note that even our longest-trained model does not appear to overfit our data and would likely benefit from additional training. “
300K, 500K step 모델은 대부분의 task에서 XLNet LARGE보다 더 나은 성능을 보였습니다. 저자들은 가장 오래 학습된 모델도 데이터에 과적합되지 않았다고 하며, 추가적인 학습으로부터 성능을 더욱 끌어올릴 수 있다고 말합니다.
5.1 GLUE Results
“For GLUE we consider two finetuning settings. In the first setting (single-task, dev) we finetune RoBERTa separately for each of the GLUE tasks, using only the training data for the corresponding task. We consider a limited hyperparameter sweep for each task, with batch sizes ∈ {16, 32} and learning rates ∈ {1e−5, 2e−5, 3e−5}, with a linear warmup for the first 6% of steps followed by a linear decay to 0. We finetune for 10 epochs and perform early stopping based on each task’s evaluation metric on the dev set. The rest of the hyperparameters remain the same as during pretraining. In this setting, we report the median development set results for each task over five random initializations, without model ensembling.”
GLUE를 평가할 첫번째 조건 ‘Single-task single models on dev’
- 각 task 별 데이터셋을 통해 fine-tunning을 진행
- batch size = 16,32
- lr = 1e-5, 2e-5, 3e-5 (linear decay 6%)
- 10 epochs (early stopping)
- ensemble 적용 X, 5개 랜덤 weight 모델의 median 사용
“In the second setting (ensembles, test), we compare RoBERTa to other approaches on the test set via the GLUE leaderboard. While many submissions to the GLUE leaderboard depend on multitask finetuning, our submission depends only on single-task finetuning. For RTE, STS and MRPC we found it helpful to finetune starting from the MNLI single-task model, rather than the baseline pretrained RoBERTa. We explore a slightly wider hyperparameter space, described in the Appendix, and ensemble between 5 and 7 models per task.”
두번째 조건 ‘Ensembles on test’
- 타 모델들의 접근법과 달리 단일 task fine-tunning
- 각 task 별로 5~7개 모델 ensemble
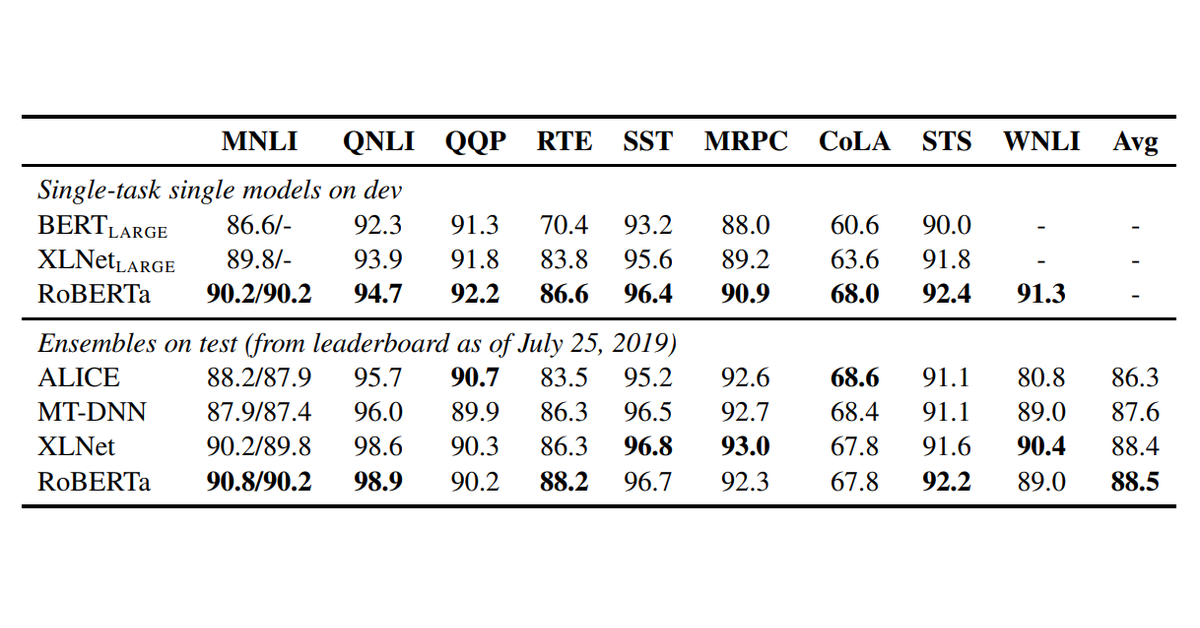
“Results We present our results in Table 5. In the first setting (single-task, dev), RoBERTa achieves state-of-the-art results on all 9 of the GLUE task development sets. Crucially, RoBERTa uses the same masked language modeling pretraining objective and architecture as BERTLARGE, yet consistently outperforms both BERTLARGE and XLNetLARGE. This raises questions about the relative importance of model architecture and pretraining objective, compared to more mundane details like dataset size and training time that we explore in this work.”
Table 5의 결과로, ‘Single-task single models on dev’에서 RoBERTa는 9개의 모든 GLUE task dev set 에서 가장 좋은 성능을 보입니다.
“In the second setting (ensembles, test), we submit RoBERTa to the GLUE leaderboard and achieve state-of-the-art results on 4 out of 9 tasks and the highest average score to date. This is especially exciting because RoBERTa does not depend on multi-task finetuning, unlike most of the other top submissions. We expect future work may further improve these results by incorporating more sophisticated multi-task finetuning procedures.”
‘ensembles, test’에서 9개 task 중 4개에서 최고 성능을 발휘합니다. RoBERTa가 타 모델과 달리 여러 작업 fine-tunning에 의존하지 않았기 때문에 향후 더 발전될 가능성이 있다고 언급합니다.
5.2 SQuAD Results
“We adopt a much simpler approach for SQuAD compared to past work. In particular, while both BERT (Devlin et al., 2019) and XLNet (Yang et al., 2019) augment their training data with additional QA datasets, we only finetune RoBERTa using the provided SQuAD training data. Yang et al. (2019) also employed a custom layer-wise learning rate schedule to finetune XLNet, while we use the same learning rate for all layers. For SQuAD v1.1 we follow the same finetuning procedure as Devlin et al. (2019). For SQuAD v2.0, we additionally classify whether a given question is answerable; we train this classifier jointly with the span predictor by summing the classification and span loss terms. “
RoBERTa는 SQuAD에서도 다른 연구와 다르게 추가적인 QA 데이터셋을 사용하지 않았습니다.
“Results We present our results in Table 6. On the SQuAD v1.1 development set, RoBERTa matches the state-of-the-art set by XLNet. On the SQuAD v2.0 development set, RoBERTa sets a new state-of-the-art, improving over XLNet by 0.4 points (EM) and 0.6 points (F1). We also submit RoBERTa to the public SQuAD 2.0 leaderboard and evaluate its performance relative to other systems. Most of the top systems build upon either BERT (Devlin et al., 2019) or XLNet (Yang et al., 2019), both of which rely on additional external training data. In contrast, our submission does not use any additional data. Our single RoBERTa model outperforms all but one of the single model submissions, and is the top scoring system among those that do not rely on data augmentation.”
위 Table 6에 결과로 나와있습니다. RoBERTa는 BERT, XLNet와 달리 외부 QA 데이터셋을 활용하지 않았음에도 SQuAD v1.1에서 XLNet인 sota와 동등한 성능을 나타내고 SQuAD v2.0에서는 sota를 달성하였습니다.
5.3 RACE Results
“In RACE, systems are provided with a passage of text, an associated question, and four candidate answers. Systems are required to classify which of the four candidate answers is correct.”
RACE는 질문에 대한 네 개의 후보 중 올바른 정답을 분류하는 task입니다.
“We modify RoBERTa for this task by concatenating each candidate answer with the corresponding question and passage. We then encode each of these four sequences and pass the resulting [CLS] representations through a fully-connected layer, which is used to predict the correct answer. We truncate question-answer pairs that are longer than 128 tokens and, if needed, the passage so that the total length is at most 512 tokens.”
RoBERTa는 각 답변을 질문과 후보 답변을 함께 연결하여 각 sequence를 만든 뒤 통과시켜 [CLS] token을 추출하고, 이를 통해 정답을 예측하도록 학습됩니다. 입력 길이는 512 token을 넘지 않도록 잘랐습니다.
“Results on the RACE test sets are presented in Table 7. RoBERTa achieves state-of-the-art results on both middle-school and high-school settings.”
그 결과로 Table 7과 같이 middle-school과 high-school 모두에서 state-of-the-art 성능을 기록했습니다.
6. Related Work
“Pretraining methods have been designed with different training objectives, including language modeling (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018), machine translation (McCann et al., 2017), and masked language modeling (Devlin et al., 2019; Lample and Conneau, 2019). Many recent papers have used a basic recipe of finetuning models for each end task (Howard and Ruder, 2018; Radford et al., 2018), and pretraining with some variant of a masked language model objective. However, newer methods have improved performance by multi-task fine tuning (Dong et al., 2019), incorporating entity embeddings (Sun et al., 2019), span prediction (Joshi et al., 2019), and multiple variants of autoregressive pretraining (Song et al., 2019; Chan et al., 2019; Yang et al., 2019). Performance is also typically improved by training bigger models on more data (Devlin et al., 2019; Baevski et al., 2019; Yang et al., 2019; Radford et al., 2019). Our goal was to replicate, simplify, and better tune the training of BERT, as a reference point for better understanding the relative performance of all of these methods.”
최근 pre-trained 기법들은 multi-task 학습, entity embedding, span 예측, autoregressive 방식으로 성능을 높혀가고 있습니다. 또한, 더 큰 모델과 더 많은 데이터를 사용하는 것이 성능 향상에 중요한 요소로 작용합니다. 저자들의 본 연구는 BERT를 재현하고 tunning 하여 다양한 pre-trained 방법의 성능을 비교할 기준을 마련하는 것을 목표로 합니다.
7. Conclusion
“We carefully evaluate a number of design decisions when pretraining BERT models. We find that performance can be substantially improved by training the model longer, with bigger batches over more data; removing the next sentence prediction objective; training on longer sequences; and dynamically changing the masking pattern applied to the training data. Our improved pretraining procedure, which we call RoBERTa, achieves state-of-the-art results on GLUE, RACE and SQuAD, without multi-task finetuning for GLUE or additional data for SQuAD. These results illustrate the importance of these previously overlooked design decisions and suggest that BERT’s pretraining objective remains competitive with recently proposed alternatives.”
결론입니다. 본 연구의 저자들은 BERT 사전학습 과정에서 training step 증가, 더 큰 batch, 더 많은 데이터셋, Next Sentence Prediction 제거, 더 긴 sequence, 그리고 dynamic masking이 성능 향상에 핵심적임을 역할을 했다고 주장합니다.
이렇게 BERT를 개선한 RoBERTa는 추가적인 외부 데이터셋, multi-task 학습 없이 GLUE, RACE, SQuAD에서 state-of-the-art 성능을 기록하였습니다. 이러한 점은 BERT의 pretraining이 여전히 최신 모델들과 경쟁력 있다는 것을 시사한다고 말합니다.