Perplexity / BLEU
Perplexity(PPL), BLEU(Bilingual Evaluation Understudy)에 대해 자세히 알아봅시다.
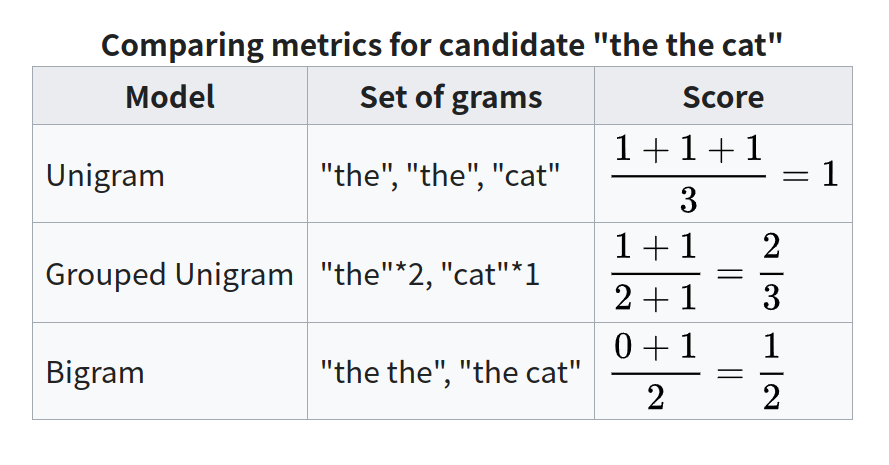
Perplexity / BLEU
Perplexity(PPL)
1. PPL (Perplexity)의 개념과 구조
1.1 기본 개념
PPL은 언어 모델의 예측 성능을 평가하는 지표로, 모델이 얼마나 자연스럽게 다음 단어를 예측하는지를 측정합니다. 핵심 아이디어는 다음과 같습니다.
- 모델의 불확실성 정도를 수치화
- 다음 단어 예측의 평균적인 난이도 측정
- 낮은 PPL일수록 더 좋은 모델을 의미
1.2 구성 요소
- 조건부 확률 \(P(w_i\|w_{1:i-1})\)
- 문장의 전체 확률
- 기하평균을 통한 정규화
2. 수학적 정의
2.1 기본 수식
PPL은 다음과 같이 정의됩니다.
\[PPL(W) = \exp(-\frac{1}{N}\sum_{i=1}^{N}\log P(w_i|w_1,...,w_{i-1}))\] \[(N: \text{전체 단어의 수})\] \[(w_i: \text{i번째 단어})\] \[(P(w_i|w_{1:i-1}): \text{이전 단어들이 주어졌을 때 현재 단어의 조건부 확률})\]2.2 Cross Entropy와의 관계
2.2.1 수학적 관계
Cross Entropy (\(H\))와 Perplexity (PPL)는 다음 관계를 가집니다.
\[PPL = 2^{H}\]2.2.2 의미 해석
Cross Entropy: 평균 정보량(bits) 측정
- 더 낮은 값 = 더 좋은 예측
- 단위: bits per word/character
PPL: Cross Entropy의 지수화된 버전
- 실제 선택 가능한 단어 수의 기하평균으로 해석
- 더 낮은 값 = 더 좋은 예측
2.2.3 변환 관계
bits 단위 사용시,
\[H = -\frac{1}{N}\sum_{i=1}^{N}\log_2 P(w_i|w_{1:i-1})\]자연로그 사용시,
\[H = -\frac{1}{N}\sum_{i=1}^{N}\ln P(w_i|w_{1:i-1})\]3. 상세 계산 예시
문장: “I love machine learning”
3.1 단계별 계산
Step 1: 각 단어의 조건부 확률 계산
1
2
3
4
P("I") = 0.1 # 문장 시작 단어로서의 확률
P("love"|"I") = 0.2 # "I" 다음에 "love"가 올 확률
P("machine"|"I love") = 0.15 # "I love" 다음에 "machine"이 올 확률
P("learning"|"I love machine") = 0.3 # "I love machine" 다음에 "learning"이 올 확률
Step 2: 로그 확률 계산
1
2
3
4
log P("I") = log(0.1) = -2.303
log P("love"|"I") = log(0.2) = -1.609
log P("machine"|"I love") = log(0.15) = -1.897
log P("learning"|"I love machine") = log(0.3) = -1.204
Step 3: 평균 로그 확률 계산
1
평균 = (-2.303 - 1.609 - 1.897 - 1.204) / 4 = -1.753
Step 4: 최종 PPL 계산
\[PPL = \exp(1.753) \approx 5.77\]4. PPL의 해석
4.1 수치 해석
1
2
3
4
PPL = 5.77의 의미
- 모델이 각 시점에서 평균적으로 5.77개의 선택지 중에서 고민
- 낮을수록 더 확신을 가지고 예측함을 의미
- 일반적으로 인간 수준의 모델은 PPL이 20~60 정도
5. PPL의 특징
5.1 장점
- 도메인에 구애받지 않는 평가 가능
- 모델의 전반적인 성능을 단일 숫자로 표현
- 다른 모델과의 직접적인 비교 가능
- 실시간 학습 과정에서의 성능 모니터링 용이
5.2 한계점
- 문맥의 의미적 적절성을 완벽히 반영하지 못함
- 도메인별 특수성을 고려하지 못함
- 희귀 단어나 신조어에 대해 불리한 평가
- 문장의 문법적 정확성을 직접적으로 평가하지 못함
- OOV(Out of Vocabulary) 문제에 취약
BLEU
1.BLEU Score
1.1 기본 개념
BLEU는 기계 번역 시스템의 출력을 평가하기 위한 자동 평가 지표입니다. 핵심 아이디어는 다음과 같습니다:
- 기계 번역문과 참조 번역문 간의 n-gram 일치도 측정
- 여러 n-gram (보통 1~4-gram)을 동시에 고려
- 번역문의 길이를 고려한 페널티 적용
1.2 구성 요소
- N-gram Precision (\(p_n\))
- Brevity Penalty (BP)
- 기하평균을 통한 최종 점수 계산
2. 수학적 정의
2.1 N-gram Precision
n-gram 정밀도는 다음과 같이 계산됩니다.
\[p_n = \frac{\sum_{ngram \in C} Count_{clip}(ngram)}{\sum_{ngram \in C} Count(ngram)}\] \[(Count_{clip}: \text{참조문에서의 최대 등장 횟수로 제한된 카운트})\] \[(Count: \text{생성문에서의 실제 등장 횟수})\]2.2 Brevity Penalty
\[BP = \begin{cases} 1 & \text{if } c > r \ e^{1-r/c} & \text{if } c \leq r \end{cases}\] \[(c: \text{생성된 번역문의 길이})\] \[(r: \text{참조 번역문의 길이})\]2.3 최종 BLEU 점수
\[BLEU = BP \cdot \exp(\sum_{n=1}^{N}w_n\log p_n)\] \[(w_n: \text{각 n-gram의 가중치, 보통 균등하게 } \frac{1}{N} \text{사용})\]3. 상세 계산 예시
참조 번역: “The cat sits on the mat” 생성된 번역: “The cat sat on the mat”
3.1 N-gram 분석
1-gram (unigram) 계산 *(‘the’는 두번 등장=> 각각 count):
1
2
3
4
5
참조문 단어: {the(2), cat(1), sits(1), on(1), mat(1)}
생성문 단어: {the(2), cat(1), sat(1), on(1), mat(1)}
Count_clip 합계: 2(the) + 1(cat) + 0(sits) + 1(on) + 1(mat) = 5
전체 생성 단어 수: 6
p₁ = 5/6 ≈ 0.833
2-gram 계산:
1
2
3
4
5
참조문 2-grams: {"the cat"(1), "cat sits"(1), "sits on"(1), "on the"(1), "the mat"(1)}
생성문 2-grams: {"the cat"(1), "cat sat"(1), "sat on"(1), "on the"(1), "the mat"(1)}
Count_clip 합계: 1("the cat") + 0("cat sat") + 0("sat on") + 1("on the") + 1("the mat") = 3
전체 생성 2-gram 수: 5
p₂ = 3/5 = 0.6
3-gram 계산:
1
2
3
4
5
참조문 3-grams: {"the cat sits"(1), "cat sits on"(1), "sits on the"(1), "on the mat"(1)}
생성문 3-grams: {"the cat sat"(1), "cat sat on"(1), "sat on the"(1), "on the mat"(1)}
Count_clip 합계: 0("the cat sat") + 0("cat sat on") + 0("sat on the") + 1("on the mat") = 1
전체 생성 3-gram 수: 4
p₃ = 1/4 = 0.25
3.2 BP 계산
- c (생성문 길이) = 6
- r (참조문 길이) = 6
- BP = 1 (같은 길이이므로)
3.3 최종 BLEU 점수 계산
균등 가중치 사용 (w₁ = w₂ = w₃ = 1/3),
\[BLEU = 1 \cdot \exp(\frac{1}{3}(\log(0.833) + \log(0.6) + \log(0.25)))\] \[= \exp(-0.606) \approx 0.545\]4. BLEU Score의 특징
4.1 장점
- 자동화된 평가 가능
- 여러 n-gram을 고려하여 문장 구조 평가
- 계산이 빠르고 비용 효율적
4.2 한계점
- 의미적 유사성 고려 못함
- 동의어 처리의 한계
- 문법적 정확성 평가의 한계
This post is licensed under CC BY 4.0 by the author.